Production Best Practices
Work through this page before going live. It covers the production configuration, machine sizing and worker strategy, Redis, and database and migrations; each section stands alone, so you can also use it as a review checklist for an existing deployment. For deeper container tuning such as alternative servers, TLS at the proxy, keepalive, and loading config from object storage, see Server Tuning.
Configuration
Set a master key
The master key is the proxy admin credential: it authenticates admin API calls and is the Admin UI login password. Set it as an env var (it must start with sk-), keep it in your secret manager, and rotate it with the master key rotation flow.
export LITELLM_MASTER_KEY="sk-<long-random-value>"
Turn on alerting
Get notified about LLM exceptions, slow or hanging requests, budget crossings, database exceptions, outages, and weekly spend reports. In the Admin UI go to Settings then Logging & Alerts, open the Alerting Types tab, toggle the alert types you want, paste your Slack webhook URL, and click Test Alerts to confirm delivery. Thresholds and report frequency live in the Alerting Settings tab next to it.
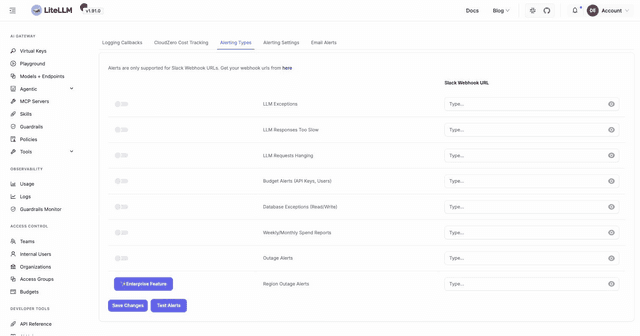
To bake it into config instead, set alerting: ["slack"] under general_settings and export SLACK_WEBHOOK_URL in the environment.
Batch spend writes
Write spend updates to the database every 60 seconds instead of on every request; at production traffic, per-request writes become a database hot spot.
general_settings:
proxy_batch_write_at: 60
Above roughly 1000 requests per second, also route these writes through Redis with the Redis transaction buffer to prevent connection exhaustion and deadlocks.
Tune config reload across pods
With store_model_in_db: true, each pod keeps itself in sync with config added at runtime (models, credentials, guardrails, general settings, etc.) by polling the database on a background job. There is no cross-pod push; a pod converges within one polling interval of a change. That interval defaults to 30 seconds and is tunable, so if you need faster convergence you can lower it, and if you run many pods against a busy database you can raise it to shed load.
general_settings:
store_model_in_db: true
proxy_config_reload_interval_seconds: 30
The value is read at startup, so a change takes effect once each pod restarts. It can also be set from the admin UI under Router Settings on the General tab, and via the PROXY_CONFIG_RELOAD_INTERVAL_SECONDS environment variable.

Bound database connections
Cap the connection pool per worker process so your instances cannot exhaust the database. Size it as MAX_DB_CONNECTIONS / (instances × workers); the default is 10.
general_settings:
database_connection_pool_limit: 10
Each instance multiplies your total connections: 3 instances × 4 workers × 10 connections = 120 total connections against your database.
Keep error logs out of the database
LLM exceptions are written to the database by default. Under sustained provider errors this bloats the spend logs table; send exceptions to your logging stack (see alerting and logging callbacks) instead.
general_settings:
disable_error_logs: True
Set a request timeout
Fail requests that hang instead of holding connections open; the default is 6000 seconds.
litellm_settings:
request_timeout: 600
Production logging
Switch off debug logging, emit JSON logs, and silence FastAPI's per-request info logs:
litellm_settings:
set_verbose: False
json_logs: true
export LITELLM_LOG="ERROR"
Disable load_dotenv
Set export LITELLM_MODE="PRODUCTION". This disables load_dotenv(), which would otherwise automatically load credentials from a local .env.
Set the salt key
If you use the database, set a salt key for encrypting and decrypting stored variables. Do not change it after adding a model; it encrypts your LLM API key credentials, and changing it makes them unreadable. Use a password generator to get a random hash.
export LITELLM_SALT_KEY="sk-1234"
Sizing and workers
Machine specifications
For optimal performance in production, we recommend the following resource configuration.
1. Memory requests and limits
resources:
requests:
cpu: "1" # should be 1*num_workers
memory: "4Gi" # should be 4*num_workers
limits:
cpu: "1"
memory: "4Gi"
2. HPA thresholds
targetCPUUtilizationPercentage: 60
targetMemoryUtilizationPercentage: 80
Workers and scaling
Run one Uvicorn worker per pod and scale horizontally (more pods) rather than vertically (more workers per pod). This is the default, so you only need --num_workers 1; one process per pod keeps latency predictable, lets the Horizontal Pod Autoscaler use the thresholds above accurately, and makes rolling restarts hitless because Kubernetes drains one pod at a time.
CMD ["--port", "4000", "--config", "./proxy_server_config.yaml", "--num_workers", "1"]
If you see gradual memory growth under sustained load, recycle each worker after a fixed number of requests with --max_requests_before_restart to bound memory usage.
CMD ["--port", "4000", "--config", "./proxy_server_config.yaml", "--num_workers", "1", "--max_requests_before_restart", "10000"]
For packing multiple workers into one container, alternative servers (Gunicorn, Hypercorn, Granian), staggering recycles with jitter, hitless rolling restarts on Kubernetes, terminating TLS at the proxy, keepalive tuning, and loading config.yaml from S3 or GCS, see Server Tuning.
Redis
Run Redis (7.0 or newer) as soon as you run more than one proxy instance. It shares rate limit counters, router state, and the response cache across instances; without it, each instance enforces limits independently and cache hits stay local to the instance that served the request.
router_settings:
routing_strategy: simple-shuffle # (default) - recommended for best performance
redis_host: os.environ/REDIS_HOST
redis_port: os.environ/REDIS_PORT
redis_password: os.environ/REDIS_PASSWORD
litellm_settings:
cache: True
cache_params:
type: redis
host: os.environ/REDIS_HOST
port: os.environ/REDIS_PORT
password: os.environ/REDIS_PASSWORD
Keep the default simple-shuffle routing strategy for high-traffic deployments; usage-based routing adds Redis lookups to the request path.
Redis transaction buffer
At very high traffic (roughly 1000+ requests per second, or 10+ instances), spend tracking itself becomes a database bottleneck: every instance issues UPDATE/UPSERT statements against the same key, user, and team rows, which causes deadlocks and can exhaust Postgres connections (FATAL: sorry, too many clients already). The transaction buffer routes those writes through Redis instead: each instance queues its spend updates in Redis, and a single instance holding a Redis-backed lock aggregates the queue and flushes it to the database in one transaction.
general_settings:
use_redis_transaction_buffer: true
Monitor it with the litellm_pod_lock_manager_size Prometheus metric (which pod holds the flush lock) and the litellm_in_memory_spend_update_queue_size / litellm_redis_spend_update_queue_size gauges (spend updates waiting in memory and in Redis; the _daily_ variants track per-user daily aggregates). If you see Got exception from REDIS No connection available under load, raise max_connections in your Redis cache_params.
Database and migrations
Gracefully handle DB unavailability
When running LiteLLM on a VPC (and inaccessible from the public internet), you can enable graceful degradation so that request processing continues even if the database is temporarily unavailable.
WARNING: Only do this if you're running LiteLLM on VPC, that cannot be accessed from the public internet.
general_settings:
allow_requests_on_db_unavailable: True
When allow_requests_on_db_unavailable is set to true, LiteLLM will handle errors as follows:
| Type of Error | Expected Behavior | Details |
|---|---|---|
| Prisma Errors | Request will be allowed | Covers issues like DB connection resets or rejections from the DB via Prisma, the ORM used by LiteLLM. |
| Httpx Errors | Request will be allowed | Occurs when the database is unreachable, allowing the request to proceed despite the DB outage. |
| Pod Startup Behavior | Pods start regardless | LiteLLM Pods will start even if the database is down or unreachable, ensuring higher uptime guarantees for deployments. |
| Health/Readiness Check | Always returns 200 OK | The /health/readiness endpoint returns a 200 OK status to ensure that pods remain operational even when the database is unavailable. |
| LiteLLM Budget Errors or Model Errors | Request will be blocked | Triggered when the DB is reachable but the authentication token is invalid, lacks access, or exceeds budget limits. |
More information about what the Database is used for here
Run migrations from the Helm PreSync hook
The Helm PreSync hook flow is in beta.
To ensure only one service manages database migrations, use our Helm PreSync hook for Database Migrations. This ensures migrations are handled during helm upgrade or helm install, while LiteLLM pods explicitly disable migrations.
- Helm PreSync Hook:
- The Helm PreSync hook is configured in the chart to run database migrations during deployments.
- The hook always sets
DISABLE_SCHEMA_UPDATE=false, ensuring migrations are executed reliably.
Reference Settings to set on ArgoCD for values.yaml
db:
useExisting: true # use existing Postgres DB
url: postgresql://ishaanjaffer0324:... # url of existing Postgres DB
-
LiteLLM Pods:
- Set
DISABLE_SCHEMA_UPDATE=truein LiteLLM pod configurations to prevent them from running migrations.
Example configuration for LiteLLM pod:
env:
- name: DISABLE_SCHEMA_UPDATE
value: "true" - Set
Use prisma migrate deploy
LiteLLM runs prisma migrate deploy on startup by default, so db migrations are handled across versions in production with no configuration. To stop a pod from running migrations at all, set DISABLE_SCHEMA_UPDATE=true as described in Run migrations from the Helm PreSync hook.
Older versions gated this behind USE_PRISMA_MIGRATE="True". That flag was removed in PR #13555 when migrate deploy became the default, and this page continued to recommend it after the fact. Setting USE_PRISMA_MIGRATE today does nothing; it is safe to remove from your environment, and removing it does not change migration behavior
The migrate deploy command:
- Does not issue a warning if an already applied migration is missing from migration history
- Does not detect drift (production database schema differs from migration history end state - for example, due to a hotfix)
- Does not reset the database or generate artifacts (such as Prisma Client)
- Does not rely on a shadow database
How LiteLLM ships migrations:
-
A new migration file is written to our
litellm-proxy-extraspackage. See all -
The core litellm pip package is bumped to point to the new
litellm-proxy-extraspackage. This ensures, older versions of LiteLLM will continue to use the old migrations. See code -
When you upgrade to a new version of LiteLLM, the migration file is applied to the database. See code
Read-only file system
Running LiteLLM with readOnlyRootFilesystem: true is a Kubernetes security best practice that prevents container processes from writing to the root filesystem. LiteLLM fully supports this configuration.
If you see a Permission denied error, it means the LiteLLM pod is running with a read-only file system. LiteLLM needs writable directories for:
- Database migrations: Set
LITELLM_MIGRATION_DIR="/path/to/writable/directory" - Admin UI: Set
LITELLM_UI_PATH="/path/to/writable/directory" - UI assets/logos: Set
LITELLM_ASSETS_PATH="/path/to/writable/directory"
Option 1: Using EmptyDir Volumes with InitContainer (Recommended)
This approach copies the pre-built UI from the Docker image to writable emptyDir volumes at pod startup.
Full Deployment manifest (initContainer, env, securityContext, volumes)
apiVersion: apps/v1
kind: Deployment
metadata:
name: litellm-proxy
spec:
template:
spec:
initContainers:
- name: setup-ui
image: ghcr.io/berriai/litellm:latest
command:
- sh
- -c
- |
cp -r /var/lib/litellm/ui/* /app/var/litellm/ui/ && \
cp -r /var/lib/litellm/assets/* /app/var/litellm/assets/
volumeMounts:
- name: ui-volume
mountPath: /app/var/litellm/ui
- name: assets-volume
mountPath: /app/var/litellm/assets
containers:
- name: litellm
image: ghcr.io/berriai/litellm:latest
env:
- name: LITELLM_NON_ROOT
value: "true"
- name: LITELLM_UI_PATH
value: "/app/var/litellm/ui"
- name: LITELLM_ASSETS_PATH
value: "/app/var/litellm/assets"
- name: LITELLM_MIGRATION_DIR
value: "/app/migrations"
- name: PRISMA_BINARY_CACHE_DIR
value: "/app/cache/prisma-python/binaries"
- name: XDG_CACHE_HOME
value: "/app/cache"
securityContext:
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 101
capabilities:
drop:
- ALL
volumeMounts:
- name: config
mountPath: /app/config.yaml
subPath: config.yaml
readOnly: true
- name: ui-volume
mountPath: /app/var/litellm/ui
- name: assets-volume
mountPath: /app/var/litellm/assets
- name: cache
mountPath: /app/cache
- name: migrations
mountPath: /app/migrations
volumes:
- name: config
configMap:
name: litellm-config
- name: ui-volume
emptyDir:
sizeLimit: 100Mi
- name: assets-volume
emptyDir:
sizeLimit: 10Mi
- name: cache
emptyDir:
sizeLimit: 500Mi
- name: migrations
emptyDir:
sizeLimit: 64Mi
Option 2: Without UI (API-only deployment)
If you don't need the admin UI, you can run with minimal configuration:
env:
- name: LITELLM_NON_ROOT
value: "true"
- name: LITELLM_MIGRATION_DIR
value: "/app/migrations"
securityContext:
readOnlyRootFilesystem: true
The proxy will log a warning about the UI but API endpoints will work normally.
Environment variables for read-only filesystems:
| Variable | Purpose | Default |
|---|---|---|
LITELLM_UI_PATH | Admin UI directory | /var/lib/litellm/ui (Docker) |
LITELLM_ASSETS_PATH | UI assets/logos | /var/lib/litellm/assets (Docker) |
LITELLM_MIGRATION_DIR | Database migrations | Package directory |
PRISMA_BINARY_CACHE_DIR | Prisma binary cache | System default |
XDG_CACHE_HOME | General cache directory | System default |
Notes: always set LITELLM_MIGRATION_DIR to a writable emptyDir path, and set PRISMA_BINARY_CACHE_DIR and XDG_CACHE_HOME to writable paths. If using a custom server_root_path, you must pre-process UI files in your Dockerfile as the proxy cannot modify files at runtime with a read-only filesystem. The UI is automatically detected as pre-restructured if it contains a .litellm_ui_ready marker file (created by the official Docker images).
Verify production readiness
Expected performance
See benchmarks here.
Confirm debug logging is off
You should only see the following level of details in logs on the proxy server:
# INFO: 192.168.2.205:11774 - "POST /chat/completions HTTP/1.1" 200 OK
# INFO: 192.168.2.205:34717 - "POST /chat/completions HTTP/1.1" 200 OK
# INFO: 192.168.2.205:29734 - "POST /chat/completions HTTP/1.1" 200 OK
Deployment FAQ
Q: Is Postgres the only supported database, or do you support other ones (like Mongo)?
A: We explored MySQL but that was hard to maintain and led to bugs for customers. Currently, PostgreSQL is our primary supported database for production deployments.
Because LiteLLM talks to the database through Prisma over the PostgreSQL wire protocol, any Postgres-wire-compatible distributed SQL database works as a drop-in replacement. YugabyteDB is used in production this way; point DATABASE_URL at its YSQL endpoint (postgresql://<user>:<password>@<host>:<port>/<dbname>) and LiteLLM runs its migrations and queries unchanged. This is a good fit if you need horizontal scale or multi-region high availability beyond what a single Postgres instance provides.
Q: If there is Postgres downtime, how does LiteLLM react? Does it fail-open or is there API downtime?
A: You can gracefully handle DB unavailability if it's on your VPC; see Gracefully handle DB unavailability above.
Need help or want dedicated support? Talk to a founder here.