Budgets, Rate Limits
Personal budgets: Create virtual keys without team_id for individual spending limits
Team budgets: Add team_id to virtual keys to utilize a team's shared budget
Team member budgets: Set individual spending limits within the team's shared budget
Agent budgets: Set rate limits (tpm/rpm) and session-level caps (iterations, dollar budget) on agents Jump
If a key belongs to a team, both the team budget and the user's personal budget are enforced. The skip_user_budget_on_team_key setting will be available in the v1.94.0 release candidate. To keep the old behavior where only the team (and team-member) budgets apply, set skip_user_budget_on_team_key: true under general_settings in config.yaml, or toggle it at runtime from the Admin UI General Settings table (Router Settings > General).
Requirements:
Set Budgets
Global Proxy
Apply a budget across all calls on the proxy
Step 1. Modify config.yaml
general_settings:
master_key: sk-1234
litellm_settings:
# other litellm settings
max_budget: 0 # (float) sets max budget as $0 USD
budget_duration: 30d # (str) frequency of reset - You can set duration as seconds ("30s"), minutes ("30m"), hours ("30h"), days ("30d").
Step 2. Start proxy
litellm /path/to/config.yaml
Step 3. Send test call
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Autherization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}'
Team
You can:
- Add budgets to Teams
Step-by step tutorial on setting, resetting budgets on Teams here (API or using Admin UI)
Add budgets to teams
curl --location 'http://localhost:4000/team/new' \
--header 'Authorization: Bearer <your-master-key>' \
--header 'Content-Type: application/json' \
--data-raw '{
"team_alias": "my-new-team_4",
"members_with_roles": [{"role": "admin", "user_id": "5c4a0aa3-a1e1-43dc-bd87-3c2da8382a3a"}],
"rpm_limit": 99
}'
Sample Response
{
"team_alias": "my-new-team_4",
"team_id": "13e83b19-f851-43fe-8e93-f96e21033100",
"admins": [],
"members": [],
"members_with_roles": [
{
"role": "admin",
"user_id": "5c4a0aa3-a1e1-43dc-bd87-3c2da8382a3a"
}
],
"metadata": {},
"tpm_limit": null,
"rpm_limit": 99,
"max_budget": null,
"models": [],
"spend": 0.0,
"max_parallel_requests": null,
"budget_duration": null,
"budget_reset_at": null
}
Add budget duration to teams
budget_duration: Budget is reset at the end of specified duration. If not set, budget is never reset. You can set duration as seconds ("30s"), minutes ("30m"), hours ("30h"), days ("30d").
curl 'http://0.0.0.0:4000/team/new' \
--header 'Authorization: Bearer <your-master-key>' \
--header 'Content-Type: application/json' \
--data-raw '{
"team_alias": "my-new-team_4",
"members_with_roles": [{"role": "admin", "user_id": "5c4a0aa3-a1e1-43dc-bd87-3c2da8382a3a"}],
"budget_duration": "30s",
}'
Team Members
Use this when you want to budget a users spend within a Team
Step 1. Create User
Create a user with user_id=ishaan
curl --location 'http://0.0.0.0:4000/user/new' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"user_id": "ishaan"
}'
Step 2. Add User to an existing Team - set max_budget_in_team
Set max_budget_in_team when adding a User to a team. We use the same user_id we set in Step 1
curl -X POST 'http://0.0.0.0:4000/team/member_add' \
-H 'Authorization: Bearer sk-1234' \
-H 'Content-Type: application/json' \
-d '{"team_id": "e8d1460f-846c-45d7-9b43-55f3cc52ac32", "max_budget_in_team": 0.000000000001, "member": {"role": "user", "user_id": "ishaan"}}'
Step 3. Create a Key for Team member from Step 1
Set user_id=ishaan from step 1
curl --location 'http://0.0.0.0:4000/key/generate' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"user_id": "ishaan",
"team_id": "e8d1460f-846c-45d7-9b43-55f3cc52ac32"
}'
Response from /key/generate
We use the key from this response in Step 4
{"key":"sk-RV-l2BJEZ_LYNChSx2EueQ", "models":[],"spend":0.0,"max_budget":null,"user_id":"ishaan","team_id":"e8d1460f-846c-45d7-9b43-55f3cc52ac32","max_parallel_requests":null,"metadata":{},"tpm_limit":null,"rpm_limit":null,"budget_duration":null,"allowed_cache_controls":[],"soft_budget":null,"key_alias":null,"duration":null,"aliases":{},"config":{},"permissions":{},"model_max_budget":{},"key_name":null,"expires":null,"token_id":null}%
Step 4. Make /chat/completions requests for Team member
Use the key from step 3 for this request. After 2-3 requests expect to see The following error ExceededBudget: Crossed spend within team
curl --location 'http://localhost:4000/chat/completions' \
--header 'Authorization: Bearer sk-RV-l2BJEZ_LYNChSx2EueQ' \
--header 'Content-Type: application/json' \
--data '{
"model": "llama3",
"messages": [
{
"role": "user",
"content": "tes4"
}
]
}'
Internal User
Apply a budget across all calls an internal user (key owner) can make on the proxy.
For keys with a team_id set, the user's personal budget is enforced alongside the team budget. The skip_user_budget_on_team_key setting will be available in the v1.94.0 release candidate. To keep the old behavior where only the team budget applies, set skip_user_budget_on_team_key: true under general_settings in config.yaml, or toggle it at runtime from the Admin UI General Settings table (Router Settings > General).
To apply a budget to a user within a team, use team member budgets.
LiteLLM exposes a /user/new endpoint to create budgets for this.
You can:
By default the max_budget is set to null and is not checked for keys
Add budgets to users
curl --location 'http://localhost:4000/user/new' \
--header 'Authorization: Bearer <your-master-key>' \
--header 'Content-Type: application/json' \
--data-raw '{"models": ["azure-models"], "max_budget": 0, "user_id": "krrish3@berri.ai"}'
Sample Response
{
"key": "sk-YF2OxDbrgd1y2KgwxmEA2w",
"expires": "2023-12-22T09:53:13.861000Z",
"user_id": "krrish3@berri.ai",
"max_budget": 0.0
}
Add budget duration to users
budget_duration: Budget is reset at the end of specified duration. If not set, budget is never reset. You can set duration as seconds ("30s"), minutes ("30m"), hours ("30h"), days ("30d").
curl 'http://0.0.0.0:4000/user/new' \
--header 'Authorization: Bearer <your-master-key>' \
--header 'Content-Type: application/json' \
--data-raw '{
"team_id": "core-infra", # [OPTIONAL]
"max_budget": 10,
"budget_duration": "30s",
}'
Create new keys for existing user
Now you can just call /key/generate with that user_id (i.e. krrish3@berri.ai) and:
- Budget Check: krrish3@berri.ai's budget (i.e. $10) will be checked for this key
- Spend Tracking: spend for this key will update krrish3@berri.ai's spend as well
curl --location 'http://0.0.0.0:4000/key/generate' \
--header 'Authorization: Bearer <your-master-key>' \
--header 'Content-Type: application/json' \
--data '{"models": ["azure-models"], "user_id": "krrish3@berri.ai"}'
Virtual Key
Apply a budget on a key.
You can:
Expected Behaviour
- Costs Per key get auto-populated in
LiteLLM_VerificationTokenTable - After the key crosses it's
max_budget, requests fail - If duration set, spend is reset at the end of the duration
By default the max_budget is set to null and is not checked for keys
Add budgets to keys
curl 'http://0.0.0.0:4000/key/generate' \
--header 'Authorization: Bearer <your-master-key>' \
--header 'Content-Type: application/json' \
--data-raw '{
"team_id": "core-infra", # [OPTIONAL]
"max_budget": 10,
}'
Example Request to /chat/completions when key has crossed budget
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer <generated-key>' \
--data ' {
"model": "azure-gpt-3.5",
"user": "e09b4da8-ed80-4b05-ac93-e16d9eb56fca",
"messages": [
{
"role": "user",
"content": "respond in 50 lines"
}
],
}'
Expected Response from /chat/completions when key has crossed budget
{
"detail":"Authentication Error, ExceededTokenBudget: Current spend for token: 7.2e-05; Max Budget for Token: 2e-07"
}
Add budget duration to keys
budget_duration: Budget is reset at the end of specified duration. If not set, budget is never reset. You can set duration as seconds ("30s"), minutes ("30m"), hours ("30h"), days ("30d").
curl 'http://0.0.0.0:4000/key/generate' \
--header 'Authorization: Bearer <your-master-key>' \
--header 'Content-Type: application/json' \
--data-raw '{
"team_id": "core-infra", # [OPTIONAL]
"max_budget": 10,
"budget_duration": "30s",
}'
Set multiple budget windows on a key
Apply multiple concurrent budget limits at different time scales on the same key — for example, cap a key at $10/day AND $100/month.
When is this useful?
A single budget_duration window can't prevent a bad day from burning your entire month. Multiple budget windows let you:
- Block a runaway usage spike within the day while still allowing normal monthly spend.
- Give Claude Code rollouts a daily guardrail (
24h) and a monthly ceiling (30d) so a single heavy session doesn't exhaust the whole month. - Layer fine-grained hourly limits for bursty workloads on top of a weekly cap.
See User Budget docs for more on how budgets work across keys, teams, and users.
Via API
Pass budget_limits as a list of {budget_duration, max_budget} objects:
curl 'http://0.0.0.0:4000/key/generate' \
--header 'Authorization: Bearer <your-master-key>' \
--header 'Content-Type: application/json' \
--data-raw '{
"budget_limits": [
{"budget_duration": "24h", "max_budget": 10},
{"budget_duration": "30d", "max_budget": 100}
]
}'
Each window is tracked independently and resets on its own schedule:
budget_duration | Resets |
|---|---|
1h | Every hour |
24h | Daily at midnight UTC |
7d | Every Sunday at midnight UTC |
30d | 1st of every month at midnight UTC |
Via Dashboard
Open Virtual Keys → Create Key → Optional Settings → Budget Windows.
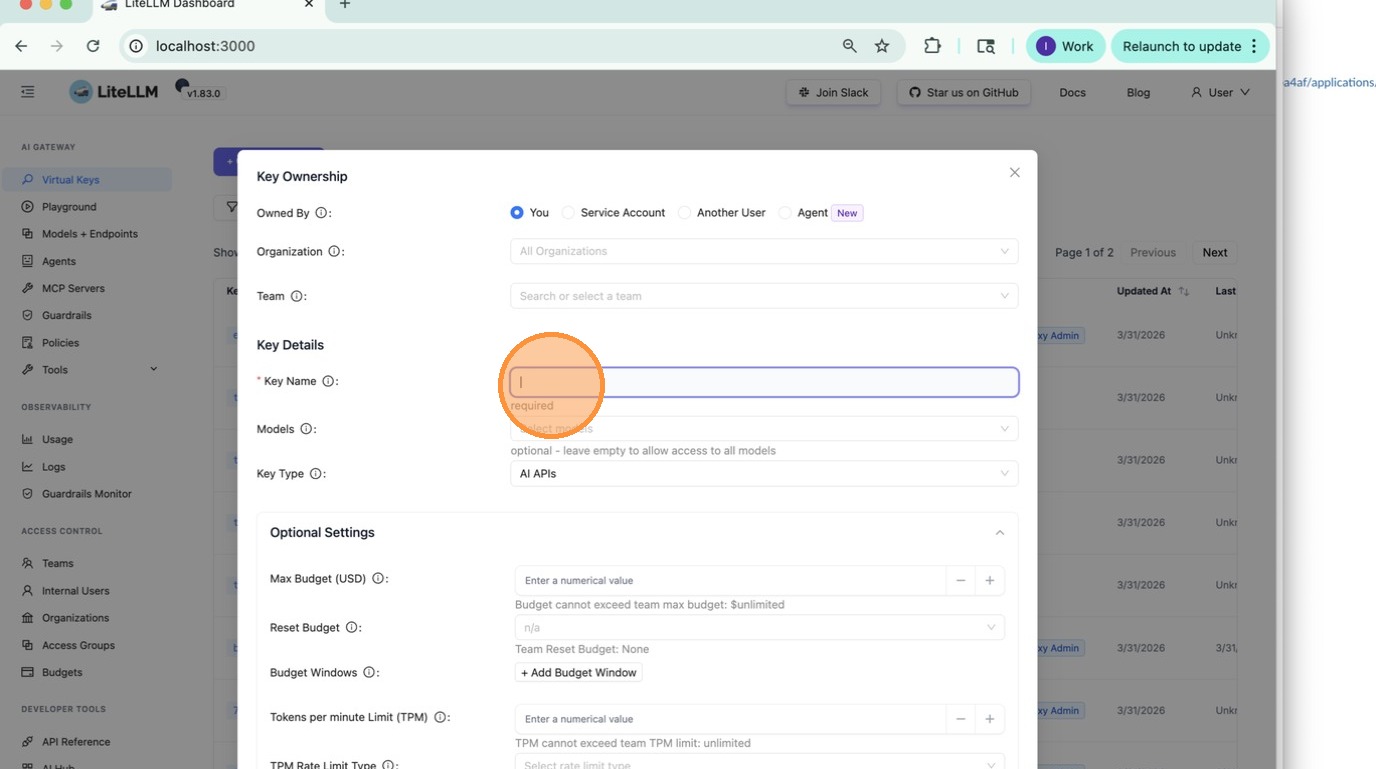
Click + Add Budget Window to add a row, choose the period from the dropdown, and enter the spend cap.
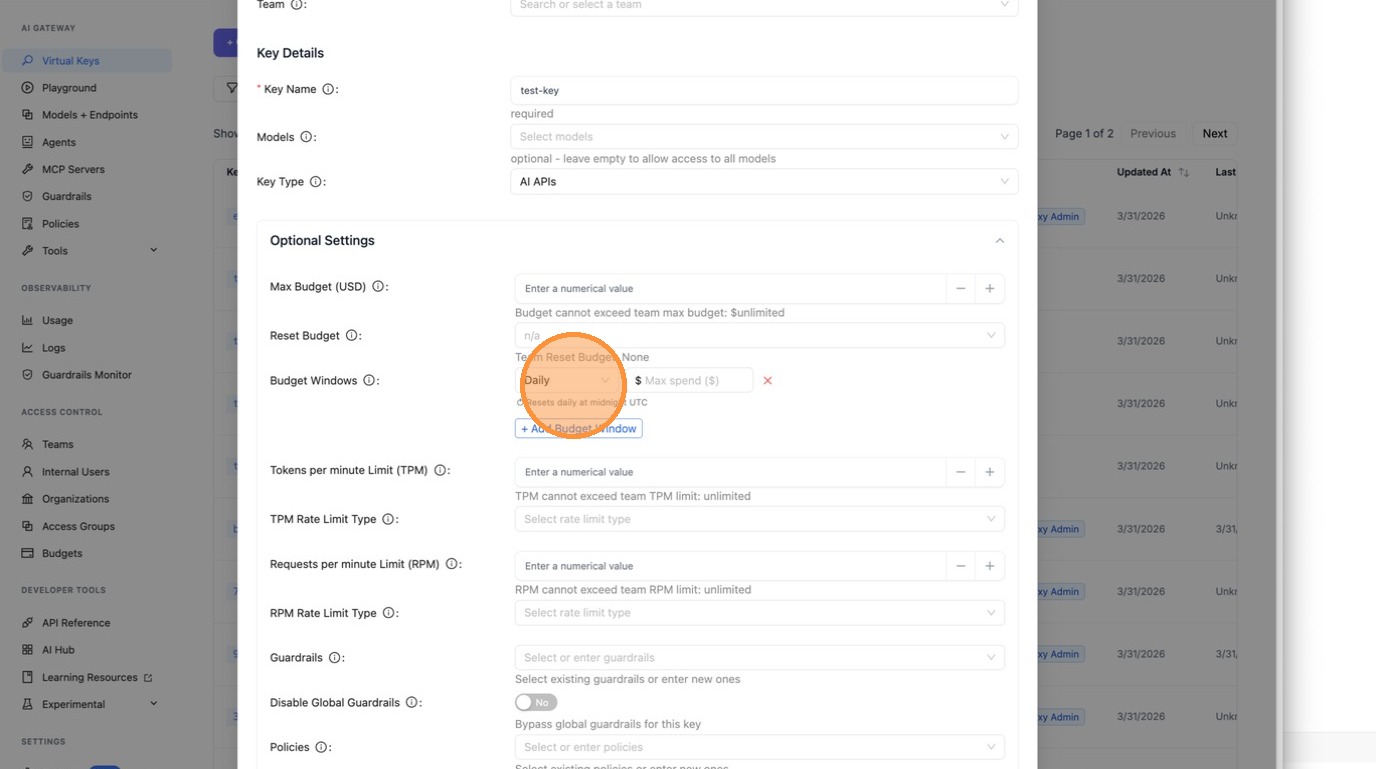
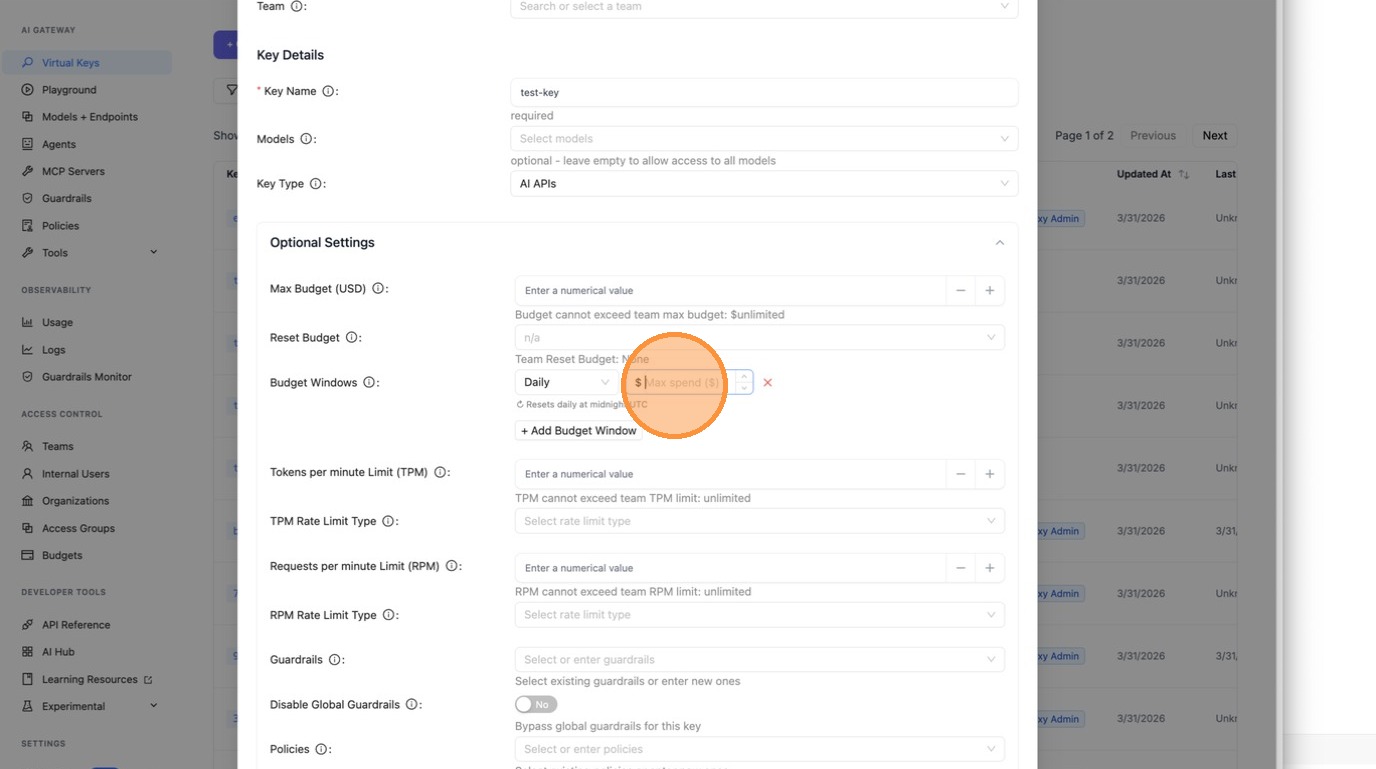
Add a second row for a different time period (e.g. monthly $100 on top of a daily $10).
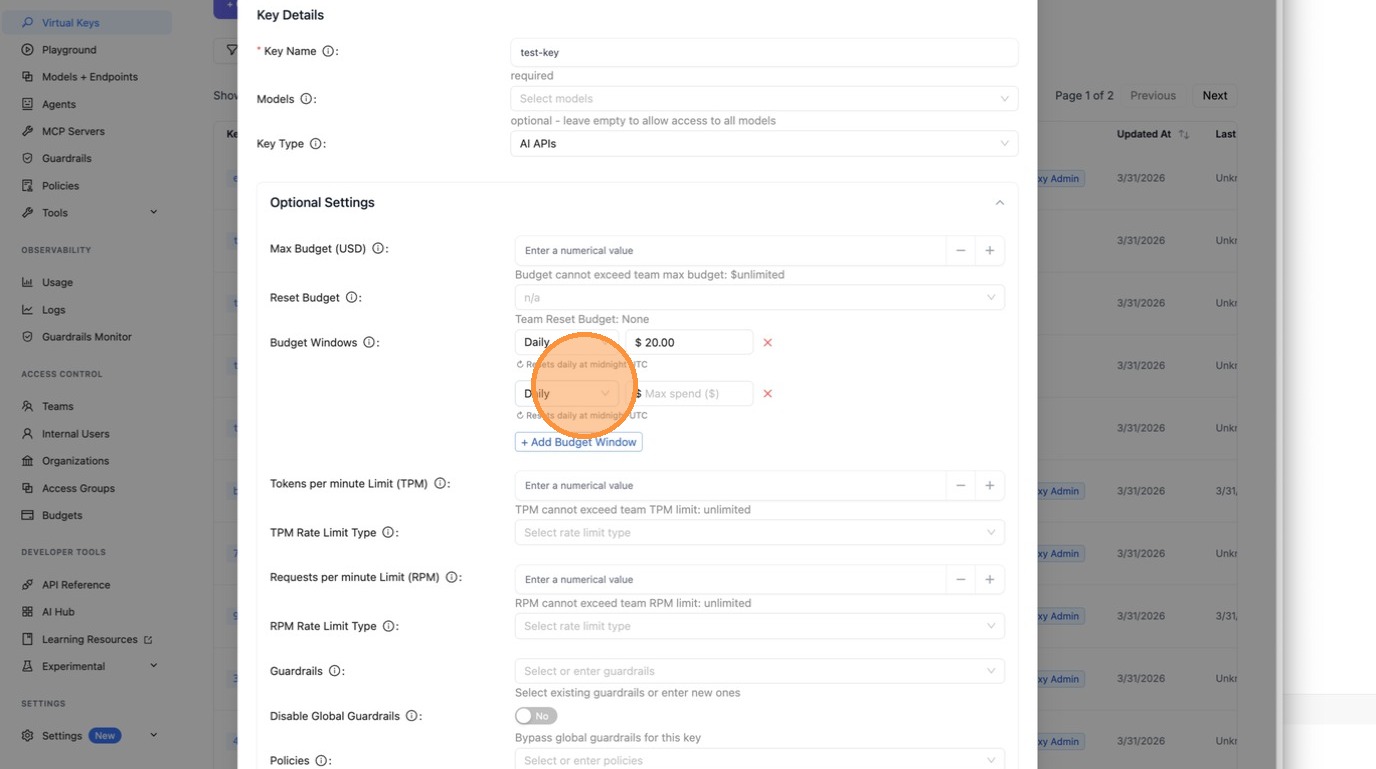
Each window shows the reset schedule below the input so it's always clear when spend resets.
✨ Virtual Key (Model Specific)
Apply model specific budgets on a key. Example:
- Budget for
gpt-4ois $0.0000001, for time period1dforkey = "sk-12345" - Budget for
gpt-4o-miniis $10, for time period30dforkey = "sk-12345"
✨ This is an Enterprise only feature Get Started with Enterprise here
The spec for model_max_budget is Dict[str, GenericBudgetInfo]
curl 'http://0.0.0.0:4000/key/generate' \
--header 'Authorization: Bearer <your-master-key>' \
--header 'Content-Type: application/json' \
--data-raw '{
"model_max_budget": {"gpt-4o": {"budget_limit": "0.0000001", "time_period": "1d"}}
}'
Make a test request
We expect the first request to succeed, and the second request to fail since we cross the budget for gpt-4o on the Virtual Key
Langchain, OpenAI SDK Usage Examples
- Successful Call
- Unsuccessful call
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer <sk-generated-key>' \
--data ' {
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": "testing request"
}
]
}
'
Expect this to fail since since we cross the budget model=gpt-4o on the Virtual Key
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer <sk-generated-key>' \
--data ' {
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": "testing request"
}
]
}
'
Expected response on failure
{
"error": {
"message": "LiteLLM Virtual Key: 9769f3f6768a199f76cc29xxxx, key_alias: None, exceeded budget for model=gpt-4o",
"type": "budget_exceeded",
"param": null,
"code": "400"
}
}
To reroute requests to another model once a per-model budget is exceeded instead of returning budget_exceeded, see Budget Fallbacks.
Agents
Set budgets and rate limits on agents registered with LiteLLM's Agent Gateway. You can control:
- Per-agent rate limits:
tpm_limitandrpm_limiton the agent itself - Per-session rate limits:
session_tpm_limitandsession_rpm_limitapplied per session - Per-session iteration cap:
max_iterationsin agentlitellm_params - Per-session budget cap:
max_budget_per_sessionin agentlitellm_params
- Agent Rate Limits
- Session Rate Limits
- Session Budgets
Set tpm_limit and rpm_limit on the agent to cap total throughput across all sessions.
curl -X POST 'http://localhost:4000/v1/agents' \
-H 'Authorization: Bearer sk-1234' \
-H 'Content-Type: application/json' \
-d '{
"agent_name": "my-research-agent",
"agent_card_params": {
"name": "my-research-agent",
"description": "A research agent",
"url": "http://my-agent:8080",
"version": "1.0.0"
},
"tpm_limit": 100000,
"rpm_limit": 100
}'
Set session_tpm_limit and session_rpm_limit to cap throughput per individual session.
curl -X POST 'http://localhost:4000/v1/agents' \
-H 'Authorization: Bearer sk-1234' \
-H 'Content-Type: application/json' \
-d '{
"agent_name": "my-research-agent",
"agent_card_params": {
"name": "my-research-agent",
"description": "A research agent",
"url": "http://my-agent:8080",
"version": "1.0.0"
},
"session_tpm_limit": 50000,
"session_rpm_limit": 50
}'
Set max_iterations and max_budget_per_session in agent litellm_params to cap individual sessions. Requires require_trace_id_on_calls_by_agent so LiteLLM can track calls per session.
curl -X POST 'http://localhost:4000/v1/agents' \
-H 'Authorization: Bearer sk-1234' \
-H 'Content-Type: application/json' \
-d '{
"agent_name": "my-research-agent",
"agent_card_params": {
"name": "my-research-agent",
"description": "A research agent",
"url": "http://my-agent:8080",
"version": "1.0.0"
},
"litellm_params": {
"require_trace_id_on_calls_by_agent": true,
"max_iterations": 25,
"max_budget_per_session": 5.00
}
}'
When a session exceeds the limit, requests receive a 429 Too Many Requests response.
See the Agent Iteration Budgets guide for full details.
You can also update rate limits on existing agents using PATCH /v1/agents/{agent_id}:
curl -X PATCH 'http://localhost:4000/v1/agents/<agent_id>' \
-H 'Authorization: Bearer sk-1234' \
-H 'Content-Type: application/json' \
-d '{
"tpm_limit": 200000,
"rpm_limit": 200,
"session_tpm_limit": 50000,
"session_rpm_limit": 50
}'
Customers
Use this to budget user passed to /chat/completions, without needing to create a key for every user
Step 1. Modify config.yaml
Define litellm.max_end_user_budget
general_settings:
master_key: sk-1234
litellm_settings:
max_end_user_budget: 0.0001 # budget for 'user' passed to /chat/completions
- Make a /chat/completions call, pass 'user' - First call Works
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer sk-zi5onDRdHGD24v0Zdn7VBA' \
--data ' {
"model": "azure-gpt-3.5",
"user": "ishaan3",
"messages": [
{
"role": "user",
"content": "what time is it"
}
]
}'
- Make a /chat/completions call, pass 'user' - Call Fails, since 'ishaan3' over budget
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer sk-zi5onDRdHGD24v0Zdn7VBA' \
--data ' {
"model": "azure-gpt-3.5",
"user": "ishaan3",
"messages": [
{
"role": "user",
"content": "what time is it"
}
]
}'
Error
{"error":{"message":"Budget has been exceeded: User ishaan3 has exceeded their budget. Current spend: 0.0008869999999999999; Max Budget: 0.0001","type":"auth_error","param":"None","code":401}}%
Reset Budgets
Reset budgets across keys/internal users/teams/customers
budget_duration: Budget is reset at the end of specified duration. If not set, budget is never reset. You can set duration as seconds ("30s"), minutes ("30m"), hours ("30h"), days ("30d").
- Internal Users
- Keys
- Teams
curl 'http://0.0.0.0:4000/user/new' \
--header 'Authorization: Bearer <your-master-key>' \
--header 'Content-Type: application/json' \
--data-raw '{
"max_budget": 10,
"budget_duration": "30s", # 👈 KEY CHANGE
}'
curl 'http://0.0.0.0:4000/key/generate' \
--header 'Authorization: Bearer <your-master-key>' \
--header 'Content-Type: application/json' \
--data-raw '{
"max_budget": 10,
"budget_duration": "30s", # 👈 KEY CHANGE
}'
curl 'http://0.0.0.0:4000/team/new' \
--header 'Authorization: Bearer <your-master-key>' \
--header 'Content-Type: application/json' \
--data-raw '{
"max_budget": 10,
"budget_duration": "30s", # 👈 KEY CHANGE
}'
Note: By default, the server checks for resets every 10 minutes, to minimize DB calls.
To change this, set proxy_budget_rescheduler_min_time and proxy_budget_rescheduler_max_time
E.g.: Check every 1 seconds
general_settings:
proxy_budget_rescheduler_min_time: 1
proxy_budget_rescheduler_max_time: 1
Fallback to 'free' models
If a key/user/team is at its budget limit, requests to models configured with input_cost_per_token: 0 and output_cost_per_token: 0 are still allowed. Budget checks are skipped entirely for zero-cost models.
This lets you configure free or self-hosted models as a fallback that budget-exhausted keys can still access.
To mark a model as free, set both cost fields explicitly to 0 in your config.yaml:
model_list:
- model_name: my-free-model
litellm_params:
model: ollama/llama3
input_cost_per_token: 0
output_cost_per_token: 0
Note: The cost fields must be explicitly set to 0. If they are unset (null/missing), the model is not treated as free and budget checks still apply.
Hard budget enforcement (fail closed)
Budget checks read current spend from a cross-pod counter in Redis, which keeps enforcement fast and consistent across workers and replicas. The counter is the source of truth on the hot path, and the database is reconciled in the background. If Redis restarts and reloads an older snapshot, the counter can come back lower than the spend already recorded in the database; on the hot path that stale value is trusted, which can let a key keep spending past its max_budget until the counter is corrected.
For deployments where a configured budget must be a hard ceiling even while Redis is degraded, set fail_closed_budget_enforcement:
general_settings:
fail_closed_budget_enforcement: true
With it enabled, every budgeted request validates spend against the authoritative database before being admitted (covering key, team, user, organization, end-user, tag, and per-window budgets), so a stale or missing Redis counter cannot under-report spend. The database read is coalesced and cached in-process for a few seconds, so the extra load is bounded to roughly one read per budgeted entity per cache window per worker rather than one read per request. If current spend can be verified against neither Redis nor the database, the request is rejected with a 503 instead of being admitted on an unverifiable budget.
Leave the setting off (the default) to keep healthy under-budget traffic entirely off the database; in the default mode the counter is still cross-checked against the database whenever it reads below the caller's last-known recorded spend, which catches the common stale-counter case without a per-request database read.
Set Rate Limits
You can set:
- tpm limits (tokens per minute)
- rpm limits (requests per minute)
- max parallel requests
- rpm / tpm limits per model for a given key or team
TPM Rate Limit Type (Input/Output/Total)
By default, TPM (tokens per minute) rate limits count total tokens (input + output). You can configure this to count only input tokens or only output tokens instead.
Set token_rate_limit_type in your config.yaml:
general_settings:
master_key: sk-1234
token_rate_limit_type: "output" # Options: "input", "output", "total" (default)
| Value | Description |
|---|---|
total | Count total tokens (prompt + completion). Default behavior. |
input | Count only prompt/input tokens |
output | Count only completion/output tokens |
This setting applies globally to all TPM rate limit checks (keys, users, teams, etc.).
- Per Team
- Per Team Per Model
- Per Internal User
- Per Key
- Per API Key Per model
- Per Agent
- For customers
Use /team/new or /team/update, to persist rate limits across multiple keys for a team.
curl --location 'http://0.0.0.0:4000/team/new' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{"team_id": "my-prod-team", "max_parallel_requests": 10, "tpm_limit": 20, "rpm_limit": 4}'
Expected Response
{
"key": "sk-sA7VDkyhlQ7m8Gt77Mbt3Q",
"expires": "2024-01-19T01:21:12.816168",
"team_id": "my-prod-team",
}
Set rate limits per model for a team
Use model_rpm_limit and model_tpm_limit to set rate limits per model for all keys belonging to a team. These limits apply across all keys in the team and are inherited by keys unless overridden at the key level.
Use /team/new or /team/update with model_rpm_limit and model_tpm_limit as dictionaries mapping model names to their limits:
curl --location 'http://0.0.0.0:4000/team/new' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"team_id": "my-prod-team",
"model_rpm_limit": {"gpt-4": 100, "gpt-3.5-turbo": 200},
"model_tpm_limit": {"gpt-4": 10000, "gpt-3.5-turbo": 20000}
}'
Update existing team with per-model limits:
curl --location 'http://0.0.0.0:4000/team/update' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"team_id": "my-prod-team",
"model_rpm_limit": {"gpt-4": 100, "gpt-3.5-turbo": 200},
"model_tpm_limit": {"gpt-4": 10000, "gpt-3.5-turbo": 20000}
}'
Alternative: Use metadata
You can also pass per-model limits via the metadata field:
curl --location 'http://0.0.0.0:4000/team/update' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"team_id": "my-prod-team",
"metadata": {
"model_rpm_limit": {"gpt-4": 100, "gpt-3.5-turbo": 200},
"model_tpm_limit": {"gpt-4": 10000, "gpt-3.5-turbo": 20000}
}
}'
Resolution order: When a key belongs to a team, rate limits are resolved as: Key metadata > Key model_max_budget > Team metadata. Keys can override team-level per-model limits with their own model_rpm_limit or model_tpm_limit.
Verify: Make a /chat/completions request and check response headers x-litellm-key-remaining-requests-{model} and x-litellm-key-remaining-tokens-{model} for the model-specific limits.
Use /user/new or /user/update, to persist rate limits across multiple keys for internal users.
curl --location 'http://0.0.0.0:4000/user/new' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{"user_id": "krrish@berri.ai", "max_parallel_requests": 10, "tpm_limit": 20, "rpm_limit": 4}'
Expected Response
{
"key": "sk-sA7VDkyhlQ7m8Gt77Mbt3Q",
"expires": "2024-01-19T01:21:12.816168",
"user_id": "krrish@berri.ai",
}
Use /key/generate, if you want them for just that key.
curl --location 'http://0.0.0.0:4000/key/generate' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{"max_parallel_requests": 10, "tpm_limit": 20, "rpm_limit": 4}'
Expected Response
{
"key": "sk-ulGNRXWtv7M0lFnnsQk0wQ",
"expires": "2024-01-18T20:48:44.297973",
"user_id": "78c2c8fc-c233-43b9-b0c3-eb931da27b84" // 👈 auto-generated
}
Set rate limits per model per api key
Set model_rpm_limit and model_tpm_limit to set rate limits per model per api key
Here gpt-4 is the model_name set on the litellm config.yaml
curl --location 'http://0.0.0.0:4000/key/generate' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{"model_rpm_limit": {"gpt-4": 2}, "model_tpm_limit": {"gpt-4":}}'
Expected Response
{
"key": "sk-ulGNRXWtv7M0lFnnsQk0wQ",
"expires": "2024-01-18T20:48:44.297973",
}
Verify Model Rate Limits set correctly for this key
Make /chat/completions request check if x-litellm-key-remaining-requests-gpt-4 returned
curl -i http://localhost:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-ulGNRXWtv7M0lFnnsQk0wQ" \
-d '{
"model": "gpt-4",
"messages": [
{"role": "user", "content": "Hello, Claude!ss eho ares"}
]
}'
Expected headers
x-litellm-key-remaining-requests-gpt-4: 1
x-litellm-key-remaining-tokens-gpt-4: 179
These headers indicate:
- 1 request remaining for the GPT-4 model for key=
sk-ulGNRXWtv7M0lFnnsQk0wQ - 179 tokens remaining for the GPT-4 model for key=
sk-ulGNRXWtv7M0lFnnsQk0wQ
Set rate limits on agents registered with the Agent Gateway.
Agent-level limits cap total throughput across all sessions:
curl -X POST 'http://0.0.0.0:4000/v1/agents' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{"agent_name": "my-agent", "agent_card_params": {"name": "my-agent", "description": "My agent", "url": "http://my-agent:8080", "version": "1.0.0"}, "tpm_limit": 100000, "rpm_limit": 100}'
Session-level limits cap throughput per individual session:
curl -X POST 'http://0.0.0.0:4000/v1/agents' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{"agent_name": "my-agent", "agent_card_params": {"name": "my-agent", "description": "My agent", "url": "http://my-agent:8080", "version": "1.0.0"}, "session_tpm_limit": 50000, "session_rpm_limit": 50}'
You can also set max_iterations (call count cap) and max_budget_per_session (dollar cap) per session via litellm_params. See Agent Iteration Budgets for details.
You can also create a budget id for a customer on the UI, under the 'Rate Limits' tab.
Use this to set rate limits for user passed to /chat/completions, without needing to create a key for every user
Step 1. Create Budget
Set a tpm_limit on the budget (You can also pass rpm_limit if needed)
curl --location 'http://0.0.0.0:4000/budget/new' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"budget_id" : "free-tier",
"tpm_limit": 5
}'
Step 2. Create Customer with Budget
We use budget_id="free-tier" from Step 1 when creating this new customers
curl --location 'http://0.0.0.0:4000/customer/new' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"user_id" : "palantir",
"budget_id": "free-tier"
}'
Step 3. Pass user_id id in /chat/completions requests
Pass the user_id from Step 2 as user="palantir"
curl --location 'http://localhost:4000/chat/completions' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"model": "llama3",
"user": "palantir",
"messages": [
{
"role": "user",
"content": "gm"
}
]
}'
Set default budget for ALL internal users
Use this to set a default budget for users who you give keys to.
This will apply when a user has user_role="internal_user" (set this via /user/new or /user/update).
This will NOT apply if a key has a team_id (team budgets will apply then). Tell us how we can improve this!
- Define max budget in your config.yaml
model_list:
- model_name: "gpt-3.5-turbo"
litellm_params:
model: gpt-3.5-turbo
api_key: os.environ/OPENAI_API_KEY
litellm_settings:
max_internal_user_budget: 0 # amount in USD
internal_user_budget_duration: "1mo" # reset every month
- Create key for user
curl -L -X POST 'http://0.0.0.0:4000/key/generate' \
-H 'Authorization: Bearer sk-1234' \
-H 'Content-Type: application/json' \
-d '{}'
Expected Response:
{
...
"key": "sk-X53RdxnDhzamRwjKXR4IHg"
}
- Test it!
curl -L -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-X53RdxnDhzamRwjKXR4IHg' \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Hey, how's it going?"}]
}'
Expected Response:
{
"error": {
"message": "ExceededBudget: User=<user_id> over budget. Spend=3.7e-05, Budget=0.0",
"type": "budget_exceeded",
"param": null,
"code": "400"
}
}
Multi-instance rate limiting
Important Notes:
- Rate limits do not apply to proxy admin users.
- When testing rate limits, use internal user roles (non-admin) to ensure limits are enforced as expected.
Changes:
- This moves to using async_increment instead of async_set_cache when updating current requests/tokens.
- The in-memory cache is synced with redis every 0.01s, to avoid calling redis for every request.
- In testing, this was found to be 2x faster than the previous implementation, and reduced drift between expected and actual fails to at most 10 requests at high-traffic (100 RPS across 3 instances).
Grant Access to new model
Use model access groups to give users access to select models, and add new ones to it over time (e.g. mistral, llama-2, etc.).
Difference between doing this with /key/generate vs. /user/new? If you do it on /user/new it'll persist across multiple keys generated for that user.
Step 1. Assign model, access group in config.yaml
model_list:
- model_name: text-embedding-ada-002
litellm_params:
model: azure/azure-embedding-model
api_base: "os.environ/AZURE_API_BASE"
api_key: "os.environ/AZURE_API_KEY"
api_version: "2023-07-01-preview"
model_info:
access_groups: ["beta-models"] # 👈 Model Access Group
Step 2. Create key with access group
curl --location 'http://localhost:4000/user/new' \
-H 'Authorization: Bearer <your-master-key>' \
-H 'Content-Type: application/json' \
-d '{"models": ["beta-models"], # 👈 Model Access Group
"max_budget": 0}'
Create new keys for existing internal user
Just include user_id in the /key/generate request.
curl --location 'http://0.0.0.0:4000/key/generate' \
--header 'Authorization: Bearer <your-master-key>' \
--header 'Content-Type: application/json' \
--data '{"models": ["azure-models"], "user_id": "krrish@berri.ai"}'
API Specification
GenericBudgetInfo
A Pydantic model that defines budget information with a time period and limit.
class GenericBudgetInfo(BaseModel):
budget_limit: float # The maximum budget amount in USD
time_period: str # Duration string like "1d", "30d", etc.
Fields:
budget_limit(float): The maximum budget amount in USDtime_period(str): Duration string specifying the time period for the budget. Supported formats:- Seconds: "30s"
- Minutes: "30m"
- Hours: "30h"
- Days: "30d"
Example:
{
"budget_limit": "0.0001",
"time_period": "1d"
}