Microservices Helm
Run LiteLLM as three independently scalable services — a gateway for LLM
traffic, a backend for the management/UI API, and a static ui — plus a
one-shot migrations Job.
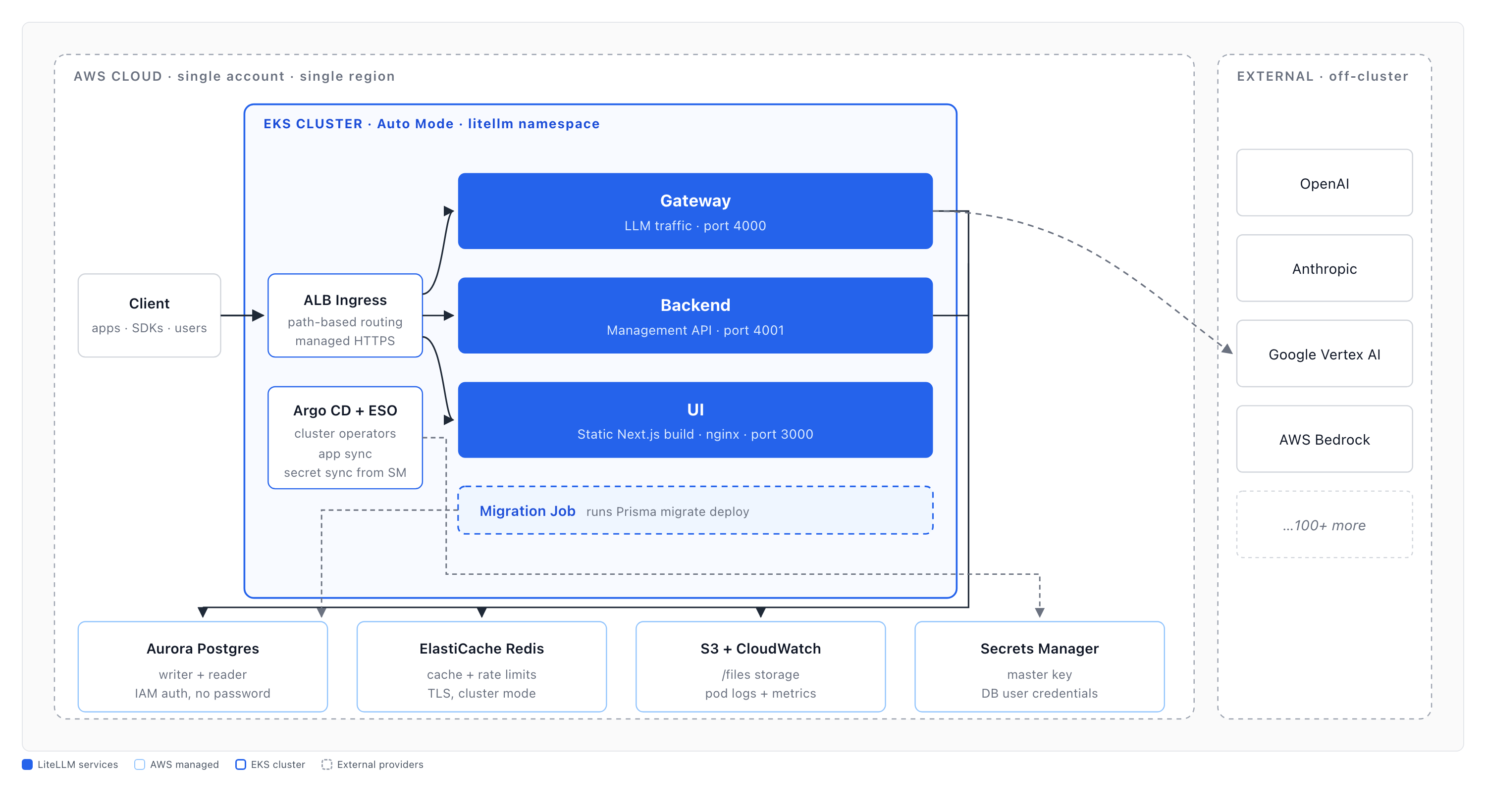
For the motivation behind splitting the proxy (why a slow control-plane query can otherwise recycle the pods serving inference), see the blog post One Slow Dashboard Query Shouldn't Take Down Your LLM Traffic.
Components
| Component | Port | Surface |
|---|---|---|
| gateway | 4000 | LLM data plane — /chat/completions, /v1/messages, embeddings, audio, batches, passthroughs, /health, /metrics |
| backend | 4001 | Management/UI API — keys, users, teams, orgs, SSO, audit logs, spend & usage analytics |
| ui | 3000 | Next.js dashboard, static export served by nginx |
| migrations | Job | prisma migrate deploy, run once as a pre-install/pre-upgrade Helm hook |
Each component is its own Deployment with its own Service, liveness/readiness probes, and HorizontalPodAutoscaler — a failure or load spike on one is contained to that surface.
Prerequisites
- A Kubernetes cluster and Helm 3.8+ (OCI registry support).
- An external Postgres database (writer endpoint; optional read replica).
- Optional: Redis for caching / rate limiting.
Install
Step 1 — Create the Secrets
Sensitive values are passed by Secret reference only — create them first:
kubectl create namespace litellm
kubectl -n litellm create secret generic litellm-master-key-secret \
--from-literal=master-key="sk-..."
kubectl -n litellm create secret generic litellm-writer-secret \
--from-literal=username=litellm --from-literal=password="..."
# Only if you use a read replica (see "Separate read and write databases")
kubectl -n litellm create secret generic litellm-reader-secret \
--from-literal=username=litellm --from-literal=password="..."
Step 2 — Minimal values.yaml
masterKey:
secretName: litellm-master-key-secret
secretKey: master-key
database:
writer:
host: litellm-pg-rw.litellm.svc
port: 5432
dbname: litellm
passwordSecret:
name: litellm-writer-secret
usernameKey: username
passwordKey: password
# Optional: front all three services behind one host
ingress:
enabled: true
className: alb
host: aigateway.example.com
Step 3 — Install from the OCI registry
The chart is published to GitHub Container Registry:
ghcr.io/berriai/litellm/chart/litellm.
helm upgrade --install litellm \
oci://ghcr.io/berriai/litellm/chart/litellm \
--version 1.86.0-dev \
-n litellm \
-f values.yaml
The chart runs prisma migrate deploy as a pre-install/pre-upgrade hook Job,
then brings up the gateway, backend, and ui Deployments. With
ingress.enabled=true a single host fronts all three: data-plane prefixes →
gateway, UI assets → ui, catch-all → backend.
Configuration
Separate read and write databases
Routing heavy analytics reads off the writer is just the database.reader
block. Set reader.host to enable it; leave it empty and every query goes to
the writer. Unset reader fields fall back to the writer's values.
database:
# Writer — all writes (spend logs, tokens, config) land here
writer:
host: litellm-pg-rw.litellm.svc
port: 5432
dbname: litellm
passwordSecret:
name: litellm-writer-secret
usernameKey: username
passwordKey: password
# Reader — read-heavy ops (find_*, count, group_by, raw reads)
reader:
host: litellm-pg-ro.litellm.svc
port: 5432
dbname: litellm
passwordSecret:
name: litellm-reader-secret
usernameKey: username
passwordKey: password
The chart assembles DATABASE_URL and DATABASE_URL_READ_REPLICA from these
pieces before the proxy starts. See
Database Read Replica for how reads are routed.
RDS / Aurora IAM auth — set useIAMAuth: true on database.writer (and
optionally database.reader) to mint short-lived IAM tokens instead of
referencing a password Secret:
database:
writer:
host: litellm.cluster-xxxx.us-east-1.rds.amazonaws.com
dbname: litellm
useIAMAuth: true
reader:
host: litellm.cluster-ro-xxxx.us-east-1.rds.amazonaws.com
useIAMAuth: true # requires database.writer.useIAMAuth: true
serviceAccount:
create: true
name: litellm
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::<acct>:role/litellm-db
Redis
Leave redis.host empty to disable. Set redis.cluster: true for Redis
Cluster mode (e.g. ElastiCache Cluster) — the chart emits REDIS_CLUSTER_NODES
from host/port as the seed and the client discovers the rest from
CLUSTER SLOTS.
redis:
cluster: true
host: litellm-redis.litellm.svc
port: 6379
passwordSecret:
name: litellm-redis-secret # leave empty for auth-less Redis
passwordKey: password
Per-component scaling and probes
Each of gateway, backend, ui accepts image, resources,
livenessProbe, readinessProbe, hpa, extraEnv, envConfigMaps,
envSecrets, logLevel, nodeSelector, tolerations, and affinity.
gateway additionally takes numWorkers (uvicorn workers per pod, default
1) and config.proxy_config (rendered into a ConfigMap and mounted at
/app/config/config.yaml).
Defaults size each surface for its own load profile:
gateway:
numWorkers: 1
hpa: { enabled: true, minReplicas: 1, maxReplicas: 10,
targetCPUUtilizationPercentage: 70, targetMemoryUtilizationPercentage: 80 }
backend:
hpa: { enabled: true, minReplicas: 1, maxReplicas: 4,
targetCPUUtilizationPercentage: 70 }
ui:
hpa: { enabled: false, minReplicas: 1, maxReplicas: 3 }
Migrations Job
Enabled by default. Runs prisma migrate deploy against the writer database as
a Helm pre-install/pre-upgrade hook, using a dedicated litellm-migrations
image. Disable it if your pipeline runs migrations out-of-band:
migrationJob:
enabled: true
backoffLimit: 4
ttlSecondsAfterFinished: 120
# The v2 resolver is used by default. To opt back into v1:
extraEnv:
- name: USE_V2_MIGRATION_RESOLVER
value: "false"
Ingress
Enable to wire the three Services behind one L7 entrypoint (required when serving the static UI over the network):
ingress:
enabled: true
className: alb
host: aigateway.example.com
annotations: {}
tls: []
The chart routes UI paths to the ui pods, data-plane prefixes to gateway,
and the catch-all (/key/*, /user/*, /spend/*, …) to backend.