Billing
Bill internal teams, external customers for their usage
🚨 Requirements
- Setup Lago, for usage-based billing. We recommend following their Stripe tutorial
Steps:
- Connect the proxy to Lago
- Set the id you want to bill for (customers, internal users, teams)
- Start!
Quick Start
Bill internal teams for their usage
1. Connect proxy to Lago
Set 'lago' as a callback on your proxy config.yaml
model_list:
- model_name: fake-openai-endpoint
litellm_params:
model: openai/fake
api_key: fake-key
api_base: https://exampleopenaiendpoint-production.up.railway.app/
litellm_settings:
callbacks: ["lago"] # 👈 KEY CHANGE
general_settings:
master_key: sk-1234
Add your Lago keys to the environment
export LAGO_API_BASE="http://localhost:3000" # self-host - https://docs.getlago.com/guide/self-hosted/docker#run-the-app
export LAGO_API_KEY="3e29d607-de54-49aa-a019-ecf585729070" # Get key - https://docs.getlago.com/guide/self-hosted/docker#find-your-api-key
export LAGO_API_EVENT_CODE="openai_tokens" # name of lago billing code
export LAGO_API_CHARGE_BY="team_id" # 👈 Charges 'team_id' attached to proxy key
Start proxy
litellm --config /path/to/config.yaml
2. Create Key for Internal Team
curl 'http://0.0.0.0:4000/key/generate' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data-raw '{"team_id": "my-unique-id"}' # 👈 Internal Team's ID
Response Object:
{
"key": "sk-tXL0wt5-lOOVK9sfY2UacA",
}
3. Start billing!
- Curl
- OpenAI Python SDK
- Langchain
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer sk-tXL0wt5-lOOVK9sfY2UacA' \ # 👈 Team's Key
--data ' {
"model": "fake-openai-endpoint",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}
'
import openai
client = openai.OpenAI(
api_key="sk-tXL0wt5-lOOVK9sfY2UacA", # 👈 Team's Key
base_url="http://0.0.0.0:4000"
)
# request sent to model set on litellm proxy, `litellm --model`
response = client.chat.completions.create(model="gpt-4o", messages = [
{
"role": "user",
"content": "this is a test request, write a short poem"
}
])
print(response)
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate,
)
from langchain.schema import HumanMessage, SystemMessage
import os
os.environ["OPENAI_API_KEY"] = "sk-tXL0wt5-lOOVK9sfY2UacA" # 👈 Team's Key
chat = ChatOpenAI(
openai_api_base="http://0.0.0.0:4000",
model = "gpt-4o",
temperature=0.1,
)
messages = [
SystemMessage(
content="You are a helpful assistant that im using to make a test request to."
),
HumanMessage(
content="test from litellm. tell me why it's amazing in 1 sentence"
),
]
response = chat(messages)
print(response)
See Results on Lago
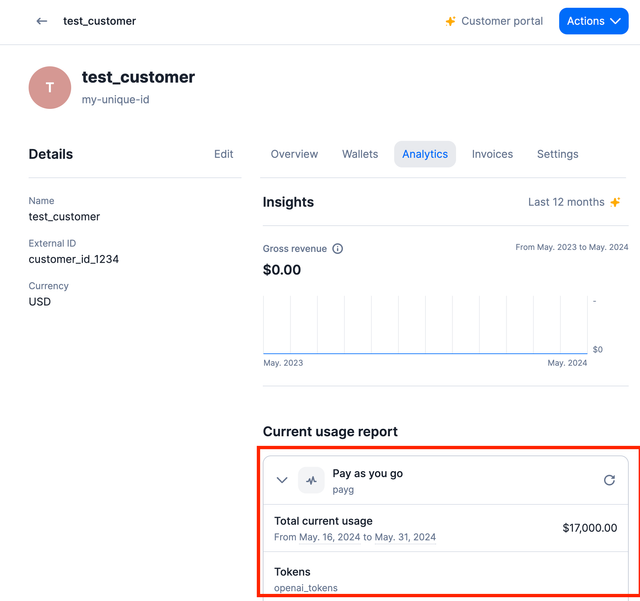
Advanced - Lago Logging object
This is what LiteLLM will log to Lagos
{
"event": {
"transaction_id": "<generated_unique_id>",
"external_customer_id": <selected_id>, # either 'end_user_id', 'user_id', or 'team_id'. Default 'end_user_id'.
"code": os.getenv("LAGO_API_EVENT_CODE"),
"properties": {
"input_tokens": <number>,
"output_tokens": <number>,
"model": <string>,
"response_cost": <number>, # 👈 LITELLM CALCULATED RESPONSE COST - https://github.com/BerriAI/litellm/blob/d43f75150a65f91f60dc2c0c9462ce3ffc713c1f/litellm/utils.py#L1473
}
}
}
Advanced - Bill Customers, Internal Users
For:
- Customers (id passed via 'user' param in /chat/completion call) = 'end_user_id'
- Internal Users (id set when creating keys) = 'user_id'
- Teams (id set when creating keys) = 'team_id'
- Customer Billing
- Internal User Billing
- Set 'LAGO_API_CHARGE_BY' to 'end_user_id'
export LAGO_API_CHARGE_BY="end_user_id"
- Test it!
- Curl
- OpenAI Python SDK
- Langchain
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
"user": "my_customer_id" # 👈 whatever your customer id is
}
'
import openai
client = openai.OpenAI(
api_key="anything",
base_url="http://0.0.0.0:4000"
)
# request sent to model set on litellm proxy, `litellm --model`
response = client.chat.completions.create(model="gpt-4o", messages = [
{
"role": "user",
"content": "this is a test request, write a short poem"
}
], user="my_customer_id") # 👈 whatever your customer id is
print(response)
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate,
)
from langchain.schema import HumanMessage, SystemMessage
import os
os.environ["OPENAI_API_KEY"] = "anything"
chat = ChatOpenAI(
openai_api_base="http://0.0.0.0:4000",
model = "gpt-4o",
temperature=0.1,
extra_body={
"user": "my_customer_id" # 👈 whatever your customer id is
}
)
messages = [
SystemMessage(
content="You are a helpful assistant that im using to make a test request to."
),
HumanMessage(
content="test from litellm. tell me why it's amazing in 1 sentence"
),
]
response = chat(messages)
print(response)
- Set 'LAGO_API_CHARGE_BY' to 'user_id'
export LAGO_API_CHARGE_BY="user_id"
- Create a key for that user
curl 'http://0.0.0.0:4000/key/generate' \
--header 'Authorization: Bearer <your-master-key>' \
--header 'Content-Type: application/json' \
--data-raw '{"user_id": "my-unique-id"}' # 👈 Internal User's id
Response Object:
{
"key": "sk-tXL0wt5-lOOVK9sfY2UacA",
}
- Make API Calls with that Key
import openai
client = openai.OpenAI(
api_key="sk-tXL0wt5-lOOVK9sfY2UacA", # 👈 Generated key
base_url="http://0.0.0.0:4000"
)
# request sent to model set on litellm proxy, `litellm --model`
response = client.chat.completions.create(model="gpt-4o", messages = [
{
"role": "user",
"content": "this is a test request, write a short poem"
}
])
print(response)