v1.70.1-stable - Gemini Realtime API Support


Deploy this version
- Docker
- Pip
docker run
-e STORE_MODEL_IN_DB=True
-p 4000:4000
docker.litellm.ai/berriai/litellm:main-v1.70.1-stable
pip install litellm==1.70.1
Key Highlights
LiteLLM v1.70.1-stable is live now. Here are the key highlights of this release:
- Gemini Realtime API: You can now call Gemini's Live API via the OpenAI /v1/realtime API
- Spend Logs Retention Period: Enable deleting spend logs older than a certain period.
- PII Masking 2.0: Easily configure masking or blocking specific PII/PHI entities on the UI
Gemini Realtime API

This release brings support for calling Gemini's realtime models (e.g. gemini-2.0-flash-live) via OpenAI's /v1/realtime API. This is great for developers as it lets them easily switch from OpenAI to Gemini by just changing the model name.
Key Highlights:
- Support for text + audio input/output
- Support for setting session configurations (modality, instructions, activity detection) in the OpenAI format
- Support for logging + usage tracking for realtime sessions
This is currently supported via Google AI Studio. We plan to release VertexAI support over the coming week.
Spend Logs Retention Period

This release enables deleting LiteLLM Spend Logs older than a certain period. Since we now enable storing the raw request/response in the logs, deleting old logs ensures the database remains performant in production.
PII Masking 2.0
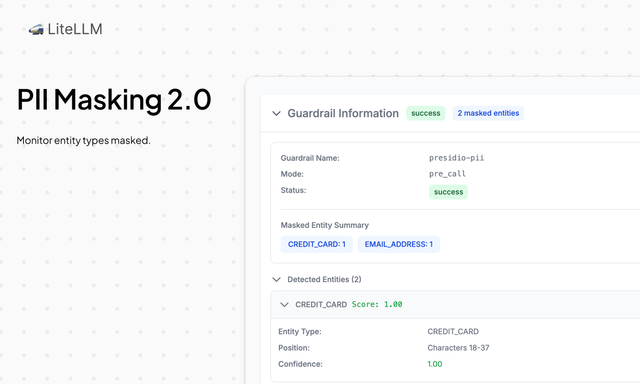
This release brings improvements to our Presidio PII Integration. As a Proxy Admin, you now have the ability to:
- Mask or block specific entities (e.g., block medical licenses while masking other entities like emails).
- Monitor guardrails in production. LiteLLM Logs will now show you the guardrail run, the entities it detected, and its confidence score for each entity.
New Models / Updated Models
- Gemini (VertexAI + Google AI Studio)
- Google AI Studio
/realtime- Gemini Multimodal Live API support
- Audio input/output support, optional param mapping, accurate usage calculation - PR
- VertexAI
/chat/completion- Fix llama streaming error - where model response was nested in returned streaming chunk - PR
- Ollama
/chat/completion- structure responses fix - PR
- Bedrock
- Nvidia NIM
/chat/completion- Add tools, tool_choice, parallel_tool_calls support - PR
- Novita AI
- New Provider added for
/chat/completionroutes - PR
- New Provider added for
- Azure
/image/generation- Fix azure dall e 3 call with custom model name - PR
- Cohere
/embeddings- Migrate embedding to use
/v2/embed- adds support for output_dimensions param - PR
- Migrate embedding to use
- Anthropic
/chat/completion- Web search tool support - native + openai format - Get Started
- VLLM
/embeddings- Support embedding input as list of integers
- OpenAI
/chat/completion- Fix - b64 file data input handling - Get Started
- Add ‘supports_pdf_input’ to all vision models - PR
LLM API Endpoints
- Responses API
- Fix delete API support - PR
- Rerank API
/v2/reranknow registered as ‘llm_api_route’ - enabling non-admins to call it - PR
Spend Tracking Improvements
/chat/completion,/messages/audio/transcription/embeddings- Azure AI - Add cohere embed v4 pricing - PR
Management Endpoints / UI
- Models
- Ollama - adds api base param to UI
- Logs
- Add team id, key alias, key hash filter on logs - https://github.com/BerriAI/litellm/pull/10831
- Guardrail tracing now in Logs UI - https://github.com/BerriAI/litellm/pull/10893
- Teams
- Patch for updating team info when team in org and members not in org - https://github.com/BerriAI/litellm/pull/10835
- Guardrails
- Add Bedrock, Presidio, Lakers guardrails on UI - https://github.com/BerriAI/litellm/pull/10874
- See guardrail info page - https://github.com/BerriAI/litellm/pull/10904
- Allow editing guardrails on UI - https://github.com/BerriAI/litellm/pull/10907
- Test Key
- select guardrails to test on UI
Logging / Alerting Integrations
- StandardLoggingPayload
- Log any
x-headers in requester metadata - Get Started - Guardrail tracing now in standard logging payload - Get Started
- Log any
- Generic API Logger
- Support passing application/json header
- Arize Phoenix
- PagerDuty
- Pagerduty is now a free feature - PR
- Alerting
- Sending slack alerts on virtual key/user/team updates is now free - PR
Guardrails
- Guardrails
- New
/apply_guardrailendpoint for directly testing a guardrail - PR
- New
- Lakera
/v2endpoints support - PR
- Presidio
- Aim Security
- Support for anonymization in AIM Guardrails - PR
Performance / Loadbalancing / Reliability improvements
- Allow overriding all constants using a .env variable - PR
- Maximum retention period for spend logs
General Proxy Improvements
- Authentication
- Handle Bearer $LITELLM_API_KEY in x-litellm-api-key custom header PR
- New Enterprise pip package -
litellm-enterprise- fixes issue whereenterprisefolder was not found when using pip package - Proxy CLI
- Add
models importcommand - PR
- Add
- OpenWebUI
- Configure LiteLLM to Parse User Headers from Open Web UI
- LiteLLM Proxy w/ LiteLLM SDK
- Option to force/always use the litellm proxy when calling via LiteLLM SDK
New Contributors
- @imdigitalashish made their first contribution in PR #10617
- @LouisShark made their first contribution in PR #10688
- @OscarSavNS made their first contribution in PR #10764
- @arizedatngo made their first contribution in PR #10654
- @jugaldb made their first contribution in PR #10805
- @daikeren made their first contribution in PR #10781
- @naliotopier made their first contribution in PR #10077
- @damienpontifex made their first contribution in PR #10813
- @Dima-Mediator made their first contribution in PR #10789
- @igtm made their first contribution in PR #10814
- @shibaboy made their first contribution in PR #10752
- @camfarineau made their first contribution in PR #10629
- @ajac-zero made their first contribution in PR #10439
- @damgem made their first contribution in PR #9802
- @hxdror made their first contribution in PR #10757
- @wwwillchen made their first contribution in PR #10894
Demo Instance
Here's a Demo Instance to test changes:
- Instance: https://demo.litellm.ai/
- Login Credentials:
- Username: admin
- Password: sk-1234