✨ Maximum Retention Period for Spend Logs
This walks through how to set the maximum retention period for spend logs. This helps manage database size by deleting old logs automatically.
Requirements
- Postgres (for log storage)
- Redis (optional) — required only if you're running multiple proxy instances and want to enable distributed locking
Usage
Setup
Add this to your proxy_config.yaml under general_settings:
general_settings:
maximum_spend_logs_retention_period: "7d" # Keep logs for 7 days
# Optional: set how frequently cleanup should run - default is daily
maximum_spend_logs_retention_interval: "1d" # Run cleanup daily
# Optional: set exact time for cleanup (Cron syntax)
maximum_spend_logs_cleanup_cron: "0 4 * * *" # Run at 04:00 AM daily
litellm_settings:
cache: true
cache_params:
type: redis
Configuration Options
maximum_spend_logs_retention_period (required)
How long logs should be kept before deletion. Supported formats:
"7d"– 7 days"24h"– 24 hours"60m"– 60 minutes"3600s"– 3600 seconds
maximum_spend_logs_retention_interval (optional)
How often the cleanup job should run. Uses the same format as above. If not set, cleanup will run every 24 hours if and only if maximum_spend_logs_retention_period is set.
maximum_spend_logs_cleanup_cron (optional)
Schedule the cleanup using standard cron syntax. This takes precedence over maximum_spend_logs_retention_interval.
Examples:
"0 4 * * *"– Run at 04:00 AM daily"0 0 * * 0"– Run at midnight every Sunday"*/30 * * * *"– Run every 30 minutes
How it works
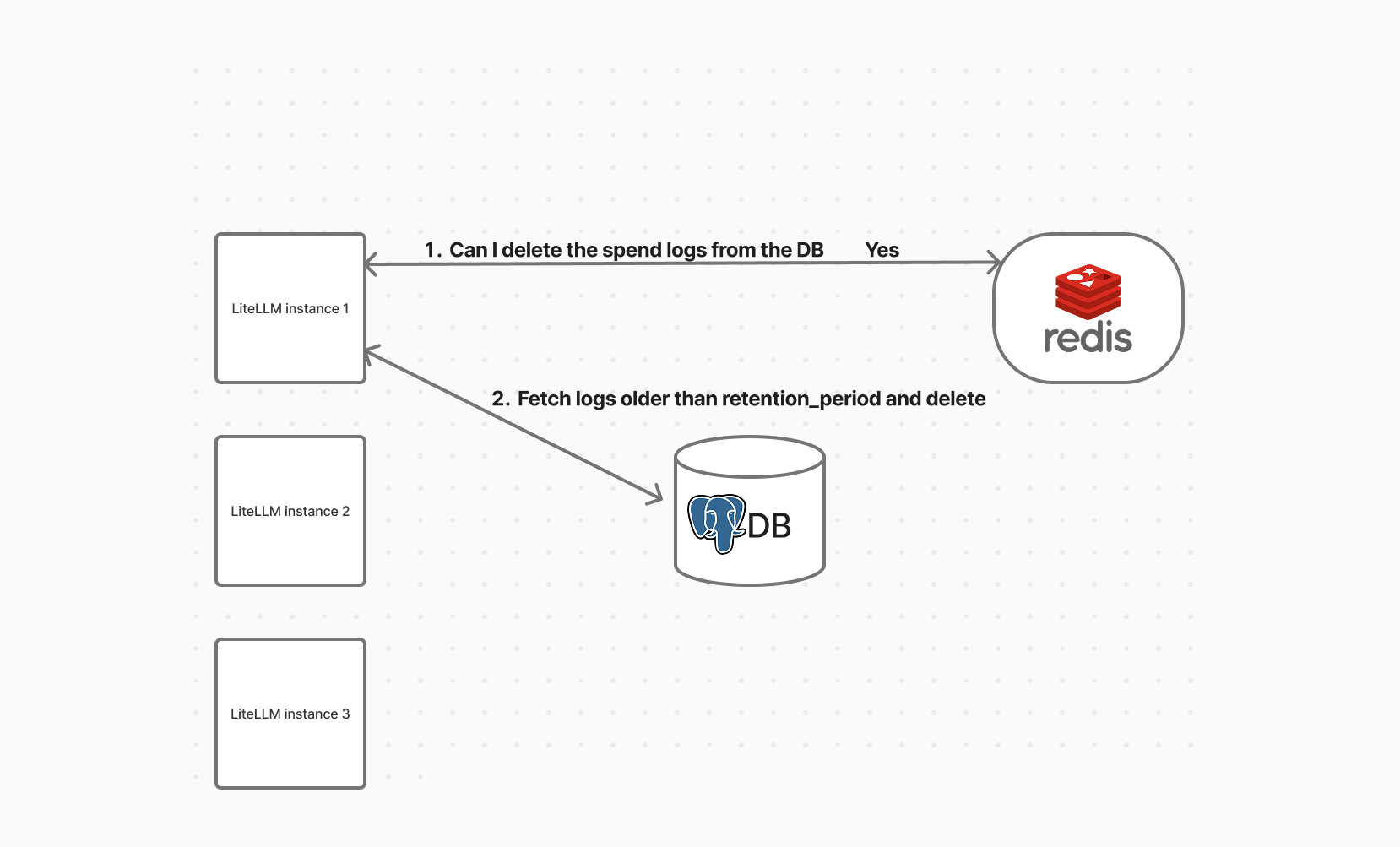
Step 1. Lock Acquisition (Optional with Redis)
If Redis is enabled, LiteLLM uses it to make sure only one instance runs the cleanup at a time.
- If the lock is acquired:
- This instance proceeds with cleanup
- Others skip it
- If no lock is present:
- Cleanup still runs (useful for single-node setups)
Working of spend log deletions
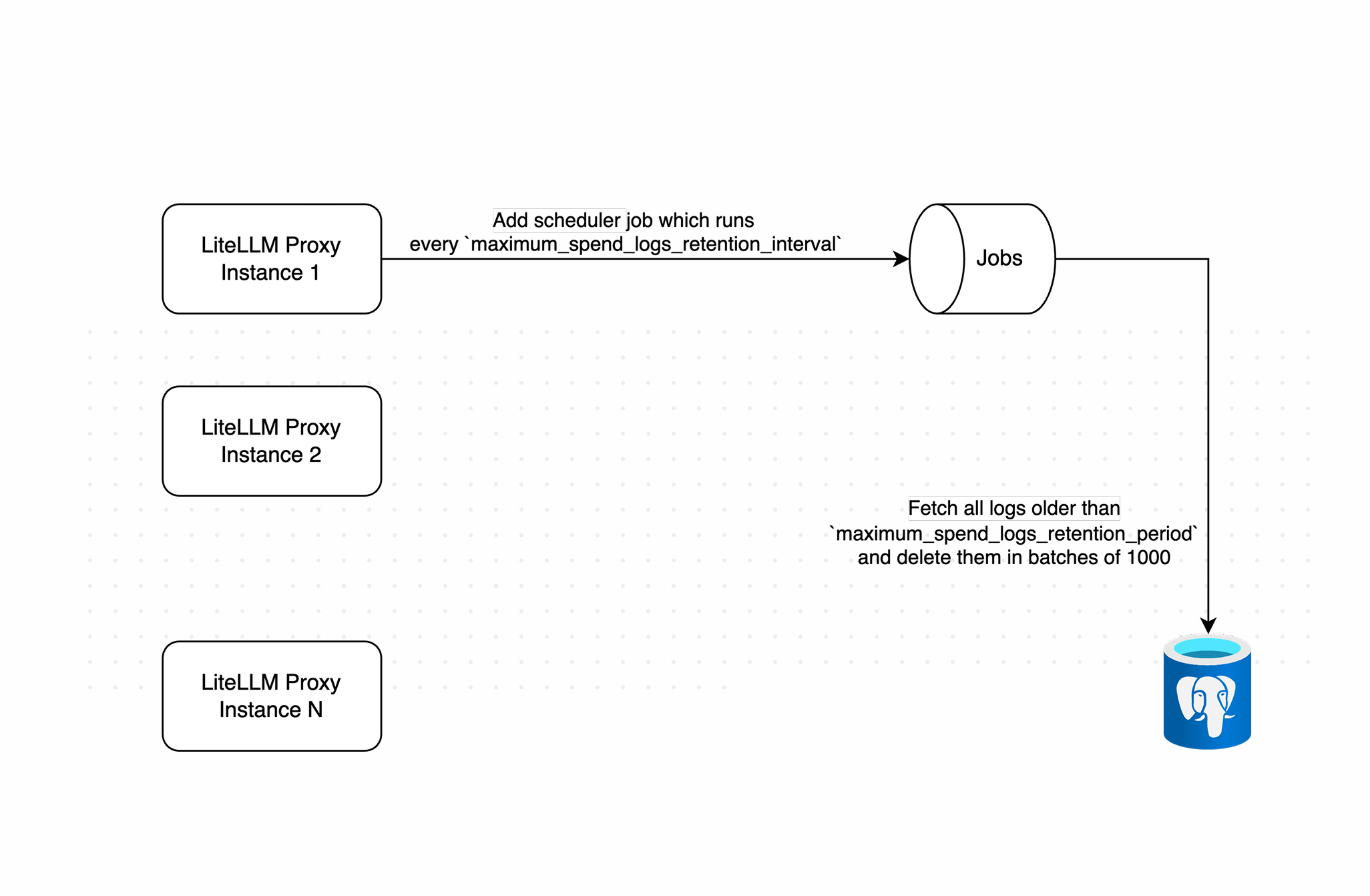
Step 2. Batch Deletion
Once cleanup starts:
- It calculates the cutoff date using the configured retention period
- Deletes logs older than the cutoff in batches (default size
1000) - Adds a short delay between batches to avoid overloading the database
Default settings:
- Batch size: 1000 logs (configurable via
SPEND_LOG_CLEANUP_BATCH_SIZE) - Max batches per run: 500
- Max deletions per run: 500,000 logs
You can change the cleanup parameters using environment variables:
SPEND_LOG_RUN_LOOPS=200
# optional: change batch size from the default 1000
SPEND_LOG_CLEANUP_BATCH_SIZE=2000
This would allow up to 200,000 logs to be deleted in one run.
Batch deletion of old logs
Partitioning for high-volume deployments
At high request volume (millions of rows per day), retention via DELETE becomes a problem. Deleting rows does not return disk to the operating system; it leaves dead tuples ("tombstones") that autovacuum has to reclaim later. When writes outpace autovacuum, the table keeps growing on disk even though the logical row count is bounded, and LiteLLM_SpendLogs can reach hundreds of GB in a month.
The fix is native Postgres range partitioning on startTime. With a partitioned table, retention drops whole partitions with DROP TABLE, an instant metadata operation that frees disk immediately, with no tombstones and no vacuum. When LiteLLM detects that LiteLLM_SpendLogs is partitioned, the same cleanup job automatically switches from batched deletes to dropping expired partitions, and it pre-creates upcoming partitions on each run so writes always have a partition to land in.
This is opt-in. The default schema is not partitioned, so existing deployments are unaffected until you convert the table.
Converting the table
Partitioning a populated table cannot be done in place, so the conversion renames the existing table aside and creates a fresh partitioned table. The partition key must be part of the primary key, so the primary key becomes the composite ("request_id", "startTime"); LiteLLM's spend-log write path uses INSERT ... ON CONFLICT DO NOTHING, which is compatible with this.
Run the runbook in db_scripts/partition_spend_logs.sql against your database (test on a staging copy and take a backup first). It creates the partitioned parent, the composite primary key, the startTime index, and a DEFAULT partition as a safety net for any out-of-range rows.
After converting, set a retention period as shown above and the cleanup job manages partitions for you.
Tuning
| Environment variable | Default | Description |
|---|---|---|
SPEND_LOG_PARTITION_INTERVAL | day | Partition granularity: day, week, or month. Use day for high-volume tables so retention is precise and individual partitions stay manageable. |
SPEND_LOG_PARTITION_PRECREATE_AHEAD | 7 | How many future partitions to pre-create on each cleanup run. |
A partition is only dropped once its entire time range is older than the retention cutoff, so effective retention is rounded up to the partition granularity.