v1.74.0-stable


Deploy this version
- Docker
- Pip
docker run \
-e STORE_MODEL_IN_DB=True \
-p 4000:4000 \
docker.litellm.ai/berriai/litellm:v1.74.0-stable
pip install litellm==1.74.0.post2
Key Highlights
- MCP Gateway Namespace Servers - Clients connecting to LiteLLM can now specify which MCP servers to use.
- Key/Team Based Logging on UI - Proxy Admins can configure team or key-based logging settings directly in the UI.
- Azure Content Safety Guardrails - Added support for prompt injection and text moderation with Azure Content Safety Guardrails.
- VertexAI Deepseek Models - Support for calling VertexAI Deepseek models with LiteLLM's/chat/completions or /responses API.
- Github Copilot API - You can now use Github Copilot as an LLM API provider.
MCP Gateway: Namespaced MCP Servers
This release brings support for namespacing MCP Servers on LiteLLM MCP Gateway. This means you can specify the x-mcp-servers header to specify which servers to list tools from.
This is useful when you want to point MCP clients to specific MCP Servers on LiteLLM.
Usage
- OpenAI API
- LiteLLM Proxy
- Cursor IDE
curl --location 'https://api.openai.com/v1/responses' \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer $OPENAI_API_KEY" \
--data '{
"model": "gpt-4o",
"tools": [
{
"type": "mcp",
"server_label": "litellm",
"server_url": "<your-litellm-proxy-base-url>/mcp",
"require_approval": "never",
"headers": {
"x-litellm-api-key": "Bearer YOUR_LITELLM_API_KEY",
"x-mcp-servers": "Zapier_Gmail"
}
}
],
"input": "Run available tools",
"tool_choice": "required"
}'
In this example, the request will only have access to tools from the "Zapier_Gmail" MCP server.
curl --location '<your-litellm-proxy-base-url>/v1/responses' \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer $LITELLM_API_KEY" \
--data '{
"model": "gpt-4o",
"tools": [
{
"type": "mcp",
"server_label": "litellm",
"server_url": "<your-litellm-proxy-base-url>/mcp",
"require_approval": "never",
"headers": {
"x-litellm-api-key": "Bearer YOUR_LITELLM_API_KEY",
"x-mcp-servers": "Zapier_Gmail,Server2"
}
}
],
"input": "Run available tools",
"tool_choice": "required"
}'
This configuration restricts the request to only use tools from the specified MCP servers.
{
"mcpServers": {
"LiteLLM": {
"url": "<your-litellm-proxy-base-url>/mcp",
"headers": {
"x-litellm-api-key": "Bearer $LITELLM_API_KEY",
"x-mcp-servers": "Zapier_Gmail,Server2"
}
}
}
}
This configuration in Cursor IDE settings will limit tool access to only the specified MCP server.
Team / Key Based Logging on UI
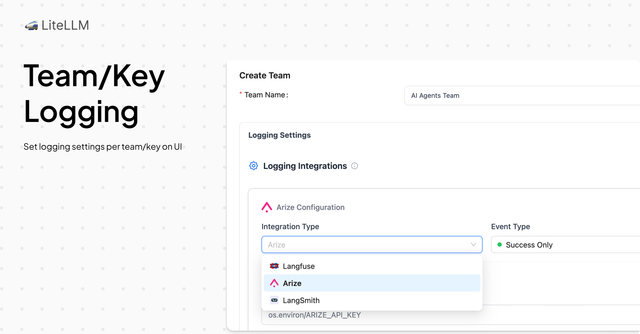
This release brings support for Proxy Admins to configure Team/Key Based Logging Settings on the UI. This allows routing LLM request/response logs to different Langfuse/Arize projects based on the team or key.
For developers using LiteLLM, their logs are automatically routed to their specific Arize/Langfuse projects. On this release, we support the following integrations for key/team based logging:
langfusearizelangsmith
Azure Content Safety Guardrails

LiteLLM now supports Azure Content Safety Guardrails for Prompt Injection and Text Moderation. This is great for internal chat-ui use cases, as you can now create guardrails with detection for Azure’s Harm Categories, specify custom severity thresholds and run them across 100+ LLMs for just that use-case (or across all your calls).
Python SDK: 2.3 Second Faster Import Times
This release brings significant performance improvements to the Python SDK with 2.3 seconds faster import times. We've refactored the initialization process to reduce startup overhead, making LiteLLM more efficient for applications that need quick initialization. This is a major improvement for applications that need to initialize LiteLLM quickly.
New Models / Updated Models
Pricing / Context Window Updates
| Provider | Model | Context Window | Input ($/1M tokens) | Output ($/1M tokens) | Type |
|---|---|---|---|---|---|
| Watsonx | watsonx/mistralai/mistral-large | 131k | $3.00 | $10.00 | New |
| Azure AI | azure_ai/cohere-rerank-v3.5 | 4k | $2.00/1k queries | - | New (Rerank) |
Features
- 🆕 GitHub Copilot - Use GitHub Copilot API with LiteLLM - PR, Get Started
- 🆕 VertexAI DeepSeek - Add support for VertexAI DeepSeek models - PR, Get Started
- Azure AI
- Add azure_ai cohere rerank v3.5 - PR, Get Started
- Vertex AI
- Add size parameter support for image generation - PR, Get Started
- Custom LLM
- Pass through extra_ properties on "custom" llm provider - PR
Bugs
- Mistral
- Gemini
- Anthropic
- Fix user_id validation logic - PR
- Bedrock
- Support optional args for bedrock - PR
- Ollama
- Fix default parameters for ollama-chat - PR
- VLLM
- Add 'audio_url' message type support - PR
LLM API Endpoints
Features
Bugs
- /v1/messages
- /chat/completions
- Support Cursor IDE tool_choice format
{"type": "auto"}- PR
- Support Cursor IDE tool_choice format
- /generateContent
- Streaming
Spend Tracking / Budget Improvements
Bugs
- Fix allow strings in calculate cost - PR
- VertexAI Anthropic streaming cost tracking with prompt caching fixes - PR
Management Endpoints / UI
Bugs
- Team Management
- UI Rendering
- Configuration
Features
- Team Management
- UI Improvements
- CLI
- Add litellm-proxy cli login for starting to use litellm proxy - PR
- Email Templates
- Customizable Email template - Subject and Signature - PR
Logging / Guardrail Integrations
Features
- Guardrails
- All guardrails are now supported on the UI - PR
- Azure Content Safety
- DeepEval
- Fix DeepEval logging format for failure events - PR
- Arize
- Add Arize Team Based Logging - PR
- Langfuse
- Langfuse prompt_version support - PR
- Sentry Integration
- Add sentry scrubbing - PR
- AWS SQS Logging
- New AWS SQS Logging Integration - PR
- S3 Logger
- Add failure logging support - PR
- Prometheus Metrics
- Add better error validation for prometheus metrics and labels - PR
Bugs
- Security
- Ensure only LLM API route fails get logged on Langfuse - PR
- OpenMeter
- Integration error handling fix - PR
- Message Redaction
- Ensure message redaction works for responses API logging - PR
- Bedrock Guardrails
- Fix bedrock guardrails post_call for streaming responses - PR
Performance / Loadbalancing / Reliability improvements
Features
- Python SDK
- Error Handling
- Add error handling for MCP tools not found or invalid server - PR
- SSL/TLS
General Proxy Improvements
New Contributors
- @wildcard made their first contribution in https://github.com/BerriAI/litellm/pull/12157
- @colesmcintosh made their first contribution in https://github.com/BerriAI/litellm/pull/12168
- @seyeong-han made their first contribution in https://github.com/BerriAI/litellm/pull/11946
- @dinggh made their first contribution in https://github.com/BerriAI/litellm/pull/12162
- @raz-alon made their first contribution in https://github.com/BerriAI/litellm/pull/11432
- @tofarr made their first contribution in https://github.com/BerriAI/litellm/pull/12200
- @szafranek made their first contribution in https://github.com/BerriAI/litellm/pull/12179
- @SamBoyd made their first contribution in https://github.com/BerriAI/litellm/pull/12147
- @lizzij made their first contribution in https://github.com/BerriAI/litellm/pull/12219
- @cipri-tom made their first contribution in https://github.com/BerriAI/litellm/pull/12201
- @zsimjee made their first contribution in https://github.com/BerriAI/litellm/pull/12185
- @jroberts2600 made their first contribution in https://github.com/BerriAI/litellm/pull/12175
- @njbrake made their first contribution in https://github.com/BerriAI/litellm/pull/12202
- @NANDINI-star made their first contribution in https://github.com/BerriAI/litellm/pull/12244
- @utsumi-fj made their first contribution in https://github.com/BerriAI/litellm/pull/12230
- @dcieslak19973 made their first contribution in https://github.com/BerriAI/litellm/pull/12283
- @hanouticelina made their first contribution in https://github.com/BerriAI/litellm/pull/12286
- @lowjiansheng made their first contribution in https://github.com/BerriAI/litellm/pull/11999
- @JoostvDoorn made their first contribution in https://github.com/BerriAI/litellm/pull/12281
- @takashiishida made their first contribution in https://github.com/BerriAI/litellm/pull/12239