PagerDuty Alerting
info
Handles two types of alerts:
- High LLM API Failure Rate. Configure X fails in Y seconds to trigger an alert.
- High Number of Hanging LLM Requests. Configure X hangs in Y seconds to trigger an alert.
Quick Start
- Set
PAGERDUTY_API_KEY="d8bxxxxx"in your environment variables.
PAGERDUTY_API_KEY="d8bxxxxx"
- Set PagerDuty Alerting in your config file.
model_list:
- model_name: "openai/*"
litellm_params:
model: "openai/*"
api_key: os.environ/OPENAI_API_KEY
general_settings:
alerting: ["pagerduty"]
alerting_args:
failure_threshold: 1 # Number of requests failing in a window
failure_threshold_window_seconds: 10 # Window in seconds
# Requests hanging threshold
hanging_threshold_seconds: 0.0000001 # Number of seconds of waiting for a response before a request is considered hanging
hanging_threshold_window_seconds: 10 # Window in seconds
- Test it
Start LiteLLM Proxy
litellm --config config.yaml
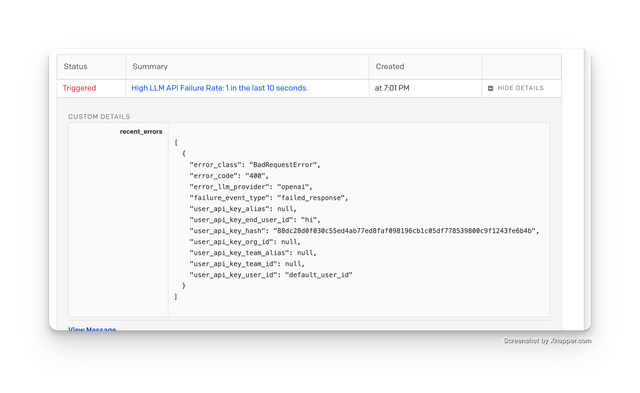
LLM API Failure Alert
Try sending a bad request to proxy
curl -i --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer sk-1234' \
--data ' {
"model": "gpt-4o",
"user": "hi",
"messages": [
{
"role": "user",
"bad_param": "i like coffee"
}
]
}
'
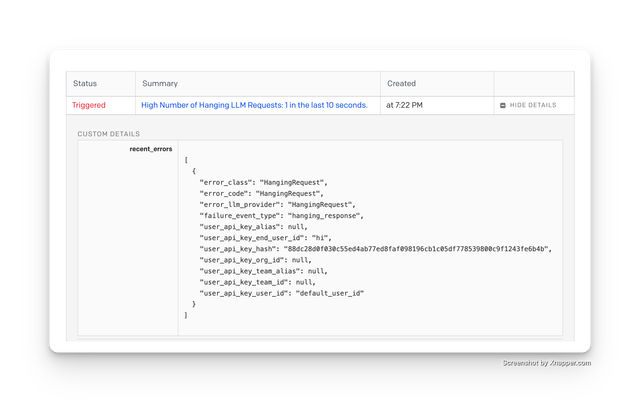
LLM Hanging Alert
Try sending a hanging request to proxy
Since our hanging threshold is 0.0000001 seconds, you should see an alert.
curl -i --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer sk-1234' \
--data ' {
"model": "gpt-4o",
"user": "hi",
"messages": [
{
"role": "user",
"content": "i like coffee"
}
]
}
'