v1.68.0-stable


Deploy this version
- Docker
- Pip
docker run litellm
docker run
-e STORE_MODEL_IN_DB=True
-p 4000:4000
docker.litellm.ai/berriai/litellm:main-v1.68.0-stable
pip install litellm
pip install litellm==1.68.0.post1
Key Highlights
LiteLLM v1.68.0-stable will be live soon. Here are the key highlights of this release:
- Bedrock Knowledge Base: You can now call query your Bedrock Knowledge Base with all LiteLLM models via
/chat/completionor/responsesAPI. - Rate Limits: This release brings accurate rate limiting across multiple instances, reducing spillover to at most 10 additional requests in high traffic.
- Meta Llama API: Added support for Meta Llama API Get Started
- LlamaFile: Added support for LlamaFile Get Started
Bedrock Knowledge Base (Vector Store)
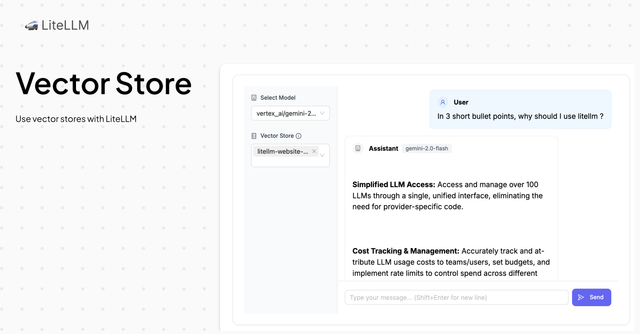
This release adds support for Bedrock vector stores (knowledge bases) in LiteLLM. With this update, you can:
- Use Bedrock vector stores in the OpenAI /chat/completions spec with all LiteLLM supported models.
- View all available vector stores through the LiteLLM UI or API.
- Configure vector stores to be always active for specific models.
- Track vector store usage in LiteLLM Logs.
For the next release we plan on allowing you to set key, user, team, org permissions for vector stores.
Rate Limiting
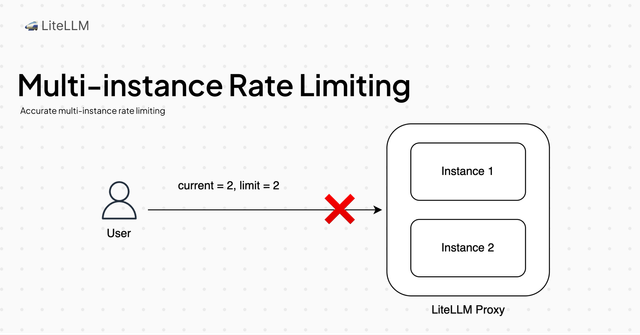
This release brings accurate multi-instance rate limiting across keys/users/teams. Outlining key engineering changes below:
- Change: Instances now increment cache value instead of setting it. To avoid calling Redis on each request, this is synced every 0.01s.
- Accuracy: In testing, we saw a maximum spill over from expected of 10 requests, in high traffic (100 RPS, 3 instances), vs. current 189 request spillover
- Performance: Our load tests show this to reduce median response time by 100ms in high traffic
This is currently behind a feature flag, and we plan to have this be the default by next week. To enable this today, just add this environment variable:
export LITELLM_RATE_LIMIT_ACCURACY=true
New Models / Updated Models
- Gemini (VertexAI + Google AI Studio)
- VertexAI
- Bedrock
- Image Generation - Support new ‘stable-image-core’ models - PR
- Knowledge Bases - support using Bedrock knowledge bases with
/chat/completionsPR - Anthropic - add ‘supports_pdf_input’ for claude-3.7-bedrock models PR, Get Started
- OpenAI
- 🆕 Meta Llama API provider PR
- 🆕 LlamaFile provider PR
LLM API Endpoints
- Response API
- Fix for handling multi turn sessions PR
- Embeddings
- Caching fixes - PR
- handle str -> list cache
- Return usage tokens for cache hit
- Combine usage tokens on partial cache hits
- Caching fixes - PR
- 🆕 Vector Stores
- MCP
- Moderations
- Add logging callback support for
/moderationsAPI - PR
- Add logging callback support for
Spend Tracking / Budget Improvements
- OpenAI
- computer-use-preview cost tracking / pricing PR
- gpt-4o-mini-tts input cost tracking - PR
- Fireworks AI - pricing updates - new
0-4bmodel pricing tier + llama4 model pricing - Budgets
- Budget resets now happen as start of day/week/month - PR
- Trigger Soft Budget Alerts When Key Crosses Threshold - PR
- Token Counting
- Rewrite of token_counter() function to handle to prevent undercounting tokens - PR
Management Endpoints / UI
- Virtual Keys
- Models
- Teams
- Allow reassigning team to other org - PR
- Organizations
- Fix showing org budget on table - PR
Logging / Guardrail Integrations
- Langsmith
- Respect langsmith_batch_size param - PR
Performance / Loadbalancing / Reliability improvements
- Redis
- Ensure all redis queues are periodically flushed, this fixes an issue where redis queue size was growing indefinitely when request tags were used - PR
- Rate Limits
- Multi-instance rate limiting support across keys/teams/users/customers - PR, PR, PR
- Azure OpenAI OIDC
General Proxy Improvements
- Security
- Allow blocking web crawlers - PR
- Auth
- Support
x-litellm-api-keyheader param by default, this fixes an issue from the prior release wherex-litellm-api-keywas not being used on vertex ai passthrough requests - PR - Allow key at max budget to call non-llm api endpoints - PR
- Support
- 🆕 Python Client Library for LiteLLM Proxy management endpoints
- Dependencies
- Don’t require uvloop for windows - PR