v1.81.0-stable - Claude Code - Web Search Across All Providers


Deploy this version
- Docker
- Pip
docker run \
-e STORE_MODEL_IN_DB=True \
-p 4000:4000 \
docker.litellm.ai/berriai/litellm:v1.81.0-stable
pip install litellm==1.81.0
Key Highlights
- Claude Code - Support for using web search across Bedrock, Vertex AI, and all LiteLLM providers
- Major Change - 50MB limit on image URL downloads to improve reliability
- Performance - 25% CPU Usage Reduction by removing premature model.dump() calls from the hot path
- Deleted Keys Audit Table on UI - View deleted keys and teams for audit purposes with spend and budget information at the time of deletion
Claude Code - Web Search Across All Providers
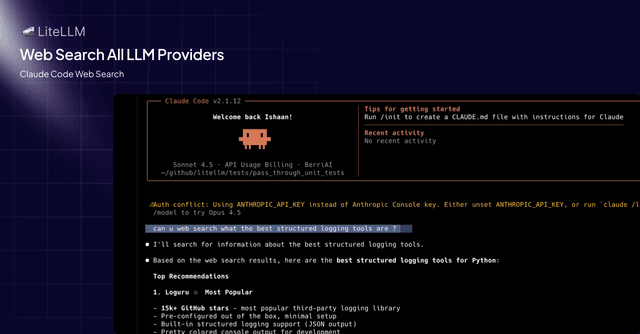
This release brings web search support to Claude Code across all LiteLLM providers (Bedrock, Azure, Vertex AI, and more), enabling AI coding assistants to search the web for real-time information.
This means you can now use Claude Code's web search tool with any provider, not just Anthropic's native API. LiteLLM automatically intercepts web search requests and executes them server-side using your configured search provider (Perplexity, Tavily, Exa AI, and more).
Proxy Admins can configure web search interception in their LiteLLM proxy config to enable this capability for their teams using Claude Code with Bedrock, Azure, or any other supported provider.
Major Change - /chat/completions Image URL Download Size Limit
To improve reliability and prevent memory issues, LiteLLM now includes a configurable 50MB limit on image URL downloads by default. Previously, there was no limit on image downloads, which could occasionally cause memory issues with very large images.
How It Works
Requests with image URLs exceeding 50MB will receive a helpful error message:
curl -X POST 'https://your-litellm-proxy.com/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-d '{
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is in this image?"
},
{
"type": "image_url",
"image_url": {
"url": "https://example.com/very-large-image.jpg"
}
}
]
}
]
}'
Error Response:
{
"error": {
"message": "Error: Image size (75.50MB) exceeds maximum allowed size (50.0MB). url=https://example.com/very-large-image.jpg",
"type": "ImageFetchError"
}
}
Configuring the Limit
The default 50MB limit works well for most use cases, but you can easily adjust it if needed:
Increase the limit (e.g., to 100MB):
export MAX_IMAGE_URL_DOWNLOAD_SIZE_MB=100
Disable image URL downloads (for security):
export MAX_IMAGE_URL_DOWNLOAD_SIZE_MB=0
Docker Configuration:
docker run \
-e MAX_IMAGE_URL_DOWNLOAD_SIZE_MB=100 \
-p 4000:4000 \
docker.litellm.ai/berriai/litellm:v1.81.0
Proxy Config (config.yaml):
general_settings:
master_key: sk-1234
# Set via environment variable
environment_variables:
MAX_IMAGE_URL_DOWNLOAD_SIZE_MB: "100"
Why Add This?
This feature improves reliability by:
- Preventing memory issues from very large images
- Aligning with OpenAI's 50MB payload limit
- Validating image sizes early (when Content-Length header is available)
Performance - 25% CPU Usage Reduction
LiteLLM now reduces CPU usage by removing premature model.dump() calls from the hot path in request processing. Previously, Pydantic model serialization was performed earlier and more frequently than necessary, causing unnecessary CPU overhead on every request. By deferring serialization until it is actually needed, LiteLLM reduces CPU usage and improves request throughput under high load.
Deleted Keys Audit Table on UI
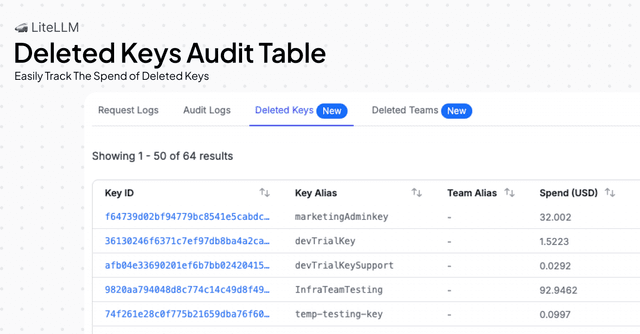
LiteLLM now provides a comprehensive audit table for deleted API keys and teams directly in the UI. This feature allows you to easily track the spend of deleted keys, view their associated team information, and maintain accurate financial records for auditing and compliance purposes. The table displays key details including key aliases, team associations, and spend information captured at the time of deletion. For more information on how to use this feature, see the Deleted Keys & Teams documentation.
New Models / Updated Models
New Model Support
| Provider | Model | Features |
|---|---|---|
| OpenAI | gpt-5.2-codex | Code generation |
| Azure | azure/gpt-5.2-codex | Code generation |
| Cerebras | cerebras/zai-glm-4.7 | Reasoning, function calling |
| Replicate | All chat models | Full support for all Replicate chat models |
Features
-
- Handle OpenAI-style image_url object in multimodal messages - PR #18272
-
- Set finish_reason to tool_calls and remove broken capability check - PR #18924
-
- Allow passing scope ID for Watsonx inferencing - PR #18959
-
- Add all chat Replicate models support - PR #18954
-
- Add OpenRouter support for image/generation endpoints - PR #19059
-
- Add max_tokens settings for Volcengine models (deepseek-v3-2, glm-4-7, kimi-k2-thinking) - PR #19076
-
Azure Model Router
- New Model - Azure Model Router on LiteLLM AI Gateway - PR #19054
-
GPT-5 Models
-
Text Completion
- Support token IDs (list of integers) as prompt - PR #18011
Bug Fixes
-
- Fix Claude Code (
/messages) Bedrock Invoke usage and request signing - PR #19111 - Fix model ID encoding for Bedrock passthrough - PR #18944
- Respect max_completion_tokens in thinking feature - PR #18946
- Fix header forwarding in Bedrock passthrough - PR #19007
- Fix Bedrock stability model usage issues - PR #19199
- Fix Claude Code (
LLM API Endpoints
Features
-
Realtime API
- Use non-streaming method for endpoint v1/a2a/message/send - PR #19025
-
Batch API
- Fix batch deletion and retrieve - PR #18340
Bugs
- General
Management Endpoints / UI
Features
Virtual Keys
- View deleted keys for audit purposes - PR #18228, PR #19268
- Add status query parameter for keys list - PR #19260
- Refetch keys after key creation - PR #18994
- Refresh keys list on delete - PR #19262
- Simplify key generate permission error - PR #18997
- Add search to key edit team dropdown - PR #19119
Teams & Organizations
- View deleted teams for audit purposes - PR #18228, PR #19268
- Add filters to organization table - PR #18916
- Add query parameters to
/organization/list- PR #18910 - Add status query parameter for teams list - PR #19260
- Show internal users their spend only - PR #19227
- Allow preventing team admins from deleting members from teams - PR #19128
- Refactor team member icon buttons - PR #19192
Models + Endpoints
- Display health information in public model hub - PR #19256, PR #19258
- Quality of life improvements for Anthropic models - PR #19058
- Create reusable model select component - PR #19164
- Edit settings model dropdown - PR #19186
- Fix model hub client side exception - PR #19045
Usage & Analytics
- Allow top virtual keys and models to show more entries - PR #19050
- Fix Y axis on model activity chart - PR #19055
- Add Team ID and Team Name in export report - PR #19047
- Add user metrics for Prometheus - PR #18785
SSO & Auth
- Allow setting custom MSFT Base URLs - PR #18977
- Allow overriding env var attribute names - PR #18998
- Fix SCIM GET /Users error and enforce SCIM 2.0 compliance - PR #17420
- Feature flag for SCIM compliance fix - PR #18878
General UI
- Add allowClear to dropdown components for better UX - PR #18778
- Add community engagement buttons - PR #19114
- UI Feedback Form - why LiteLLM - PR #18999
- Refactor user and team table filters to reusable component - PR #19010
- Adjusting new badges - PR #19278
Bugs
- Container API routes return 401 for non-admin users - routes missing from openai_routes - PR #19115
- Allow routing to regional endpoints for Containers API - PR #19118
- Fix Azure Storage circular reference error - PR #19120
- Fix prompt deletion fails with Prisma FieldNotFoundError - PR #18966
AI Integrations
Logging
-
- Update semantic conventions to 1.38 (gen_ai attributes) - PR #18793
-
- Hoist thread grouping metadata (session_id, thread) - PR #18982
-
- Include Langfuse logger in JSON logging when Langfuse callback is used - PR #19162
-
- Add ability to customize Logfire base URL through env var - PR #19148
-
General Logging
Guardrails
-
- Implement fail-open option (default: True) - PR #18266
-
- Respect
default_onduring initialization - PR #18912
- Respect
-
- Add custom violation message support - PR #19272
-
General Guardrails
- Fix SerializationIterator error and pass tools to guardrail - PR #18932
- Properly handle custom guardrails parameters - PR #18978
- Use clean error messages for blocked requests - PR #19023
- Guardrail moderation support with responses API - PR #18957
- Fix model-level guardrails not taking effect - PR #18895
Spend Tracking, Budgets and Rate Limiting
-
Cost Calculation Fixes
- Include IMAGE token count in cost calculation for Gemini models - PR #18876
- Fix negative text_tokens when using cache with images - PR #18768
- Fix image tokens spend logging for
/images/generations- PR #19009 - Fix incorrect
prompt_tokens_detailsin Gemini Image Generation - PR #19070 - Fix case-insensitive model cost map lookup - PR #18208
-
Pricing Updates
- Correct pricing for
openrouter/openai/gpt-oss-20b- PR #18899 - Add pricing for
azure_ai/claude-opus-4-5- PR #19003 - Update Novita models prices - PR #19005
- Fix Azure Grok prices - PR #19102
- Fix GCP GLM-4.7 pricing - PR #19172
- Sync DeepSeek chat/reasoner to V3.2 pricing - PR #18884
- Correct cache_read pricing for gemini-2.5-pro models - PR #18157
- Correct pricing for
-
Budget & Rate Limiting
MCP Gateway
- Prevent duplicate MCP reload scheduler registration - PR #18934
- Forward MCP extra headers case-insensitively - PR #18940
- Fix MCP REST auth checks - PR #19051
- Fix generating two telemetry events in responses - PR #18938
- Fix MCP chat completions - PR #19129
Performance / Loadbalancing / Reliability improvements
-
Performance Improvements
- Remove bottleneck causing high CPU usage & overhead under heavy load - PR #19049
- Add CI enforcement for O(1) operations in
_get_model_cost_keyto prevent performance regressions - PR #19052 - Fix Azure embeddings JSON parsing to prevent connection leaks and ensure proper router cooldown - PR #19167
- Do not fallback to token counter if
disable_token_counteris enabled - PR #19041
-
Reliability
-
Infrastructure
-
Helm Chart
Database Changes
Schema Updates
| Table | Change Type | Description | PR |
|---|---|---|---|
LiteLLM_ProxyModelTable | New Columns | Added created_at and updated_at timestamp fields | PR #18937 |
Documentation Updates
- Add LiteLLM architecture md doc - PR #19057, PR #19252
- Add troubleshooting guide - PR #19096, PR #19097, PR #19099
- Add structured issue reporting guides for CPU and memory issues - PR #19117
- Add Redis requirement warning for high-traffic deployments - PR #18892
- Update load balancing and routing with enable_pre_call_checks - PR #18888
- Updated pass_through with guided param - PR #18886
- Update message content types link and add content types table - PR #18209
- Add Redis initialization with kwargs - PR #19183
- Improve documentation for routing LLM calls via SAP Gen AI Hub - PR #19166
- Deleted Keys and Teams docs - PR #19291
- Claude Code end user tracking guide - PR #19176
- Add MCP troubleshooting guide - PR #19122
- Add auth message UI documentation - PR #19063
- Add guide for mounting custom callbacks in Helm/K8s - PR #19136
Bug Fixes
- Fix Swagger UI path execute error with server_root_path in OpenAPI schema - PR #18947
- Normalize OpenAI SDK BaseModel choices/messages to avoid Pydantic serializer warnings - PR #18972
- Add contextual gap checks and word-form digits - PR #18301
- Clean up orphaned files from repository root - PR #19150
- Include proxy/prisma_migration.py in non-root - PR #18971
- Update prisma_migration.py - PR #19083
New Contributors
- @yogeshwaran10 made their first contribution in PR #18898
- @theonlypal made their first contribution in PR #18937
- @jonmagic made their first contribution in PR #18935
- @houdataali made their first contribution in PR #19025
- @hummat made their first contribution in PR #18972
- @berkeyalciin made their first contribution in PR #18966
- @MateuszOssGit made their first contribution in PR #18959
- @xfan001 made their first contribution in PR #18947
- @nulone made their first contribution in PR #18884
- @debnil-mercor made their first contribution in PR #18919
- @hakhundov made their first contribution in PR #17420
- @rohanwinsor made their first contribution in PR #19078
- @pgolm made their first contribution in PR #19020
- @vikigenius made their first contribution in PR #19148
- @burnerburnerburnerman made their first contribution in PR #19090
- @yfge made their first contribution in PR #19076
- @danielnyari-seon made their first contribution in PR #19083
- @guilherme-segantini made their first contribution in PR #19166
- @jgreek made their first contribution in PR #19147
- @anand-kamble made their first contribution in PR #19193
- @neubig made their first contribution in PR #19162