v1.80.0-stable - Introducing Agent Hub: Register, Publish, and Share Agents


Deploy this version
- Docker
- Pip
docker run \
-e STORE_MODEL_IN_DB=True \
-p 4000:4000 \
docker.litellm.ai/berriai/litellm:v1.80.0-stable
pip install litellm==1.80.0
Key Highlights
- 🆕 Agent Hub Support - Register and make agents public for your organization
- RunwayML Provider - Complete video generation, image generation, and text-to-speech support
- GPT-5.1 Family Support - Day-0 support for OpenAI's latest GPT-5.1 and GPT-5.1-Codex models
- Prometheus OSS - Prometheus metrics now available in open-source version
- Vector Store Files API - Complete OpenAI-compatible Vector Store Files API with full CRUD operations
- Embeddings Performance - O(1) lookup optimization for router embeddings with shared sessions
Agent Hub
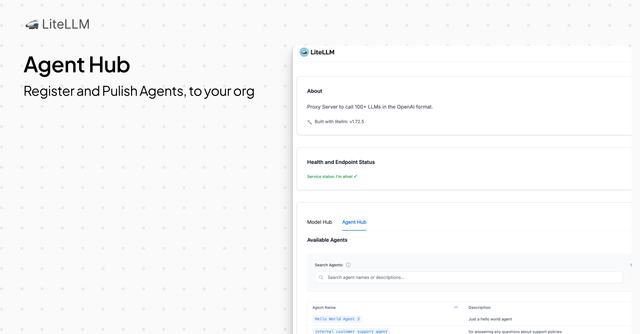
This release adds support for registering and making agents public for your organization. This is great for Proxy Admins who want a central place to make agents built in their organization, discoverable to their users.
Here's the flow:
- Add agent to litellm.
- Make it public.
- Allow anyone to discover it on the public AI Hub page.
Performance – /embeddings 13× Lower p95 Latency
This update significantly improves /embeddings latency by routing it through the same optimized pipeline as /chat/completions, benefiting from all previously applied networking optimizations.
Results
| Metric | Before | After | Improvement |
|---|---|---|---|
| p95 latency | 5,700 ms | 430 ms | −92% (~13× faster)** |
| p99 latency | 7,200 ms | 780 ms | −89% |
| Average latency | 844 ms | 262 ms | −69% |
| Median latency | 290 ms | 230 ms | −21% |
| RPS | 1,216.7 | 1,219.7 | +0.25% |
Test Setup
| Category | Specification |
|---|---|
| Load Testing | Locust: 1,000 concurrent users, 500 ramp-up |
| System | 4 vCPUs, 8 GB RAM, 4 workers, 4 instances |
| Database | PostgreSQL (Redis unused) |
| Configuration | config.yaml |
| Load Script | no_cache_hits.py |
🆕 RunwayML
Complete integration for RunwayML's Gen-4 family of models, supporting video generation, image generation, and text-to-speech.
Supported Endpoints:
/v1/videos- Video generation (Gen-4 Turbo, Gen-4 Aleph, Gen-3A Turbo)/v1/images/generations- Image generation (Gen-4 Image, Gen-4 Image Turbo)/v1/audio/speech- Text-to-speech (ElevenLabs Multilingual v2)
Quick Start:
curl --location 'http://localhost:4000/v1/videos' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer sk-1234' \
--data '{
"model": "runwayml/gen4_turbo",
"prompt": "A high quality demo video of litellm ai gateway",
"input_reference": "https://example.com/image.jpg",
"seconds": 5,
"size": "1280x720"
}'
Prometheus Metrics - Open Source
Prometheus metrics are now available in the open-source version of LiteLLM, providing comprehensive observability for your AI Gateway without requiring an enterprise license.
Quick Start:
litellm_settings:
success_callback: ["prometheus"]
failure_callback: ["prometheus"]
Vector Store Files API
Complete OpenAI-compatible Vector Store Files API now stable, enabling full file lifecycle management within vector stores.
Supported Endpoints:
POST /v1/vector_stores/{vector_store_id}/files- Create vector store fileGET /v1/vector_stores/{vector_store_id}/files- List vector store filesGET /v1/vector_stores/{vector_store_id}/files/{file_id}- Retrieve vector store fileGET /v1/vector_stores/{vector_store_id}/files/{file_id}/content- Retrieve file contentDELETE /v1/vector_stores/{vector_store_id}/files/{file_id}- Delete vector store fileDELETE /v1/vector_stores/{vector_store_id}- Delete vector store
Quick Start:
curl --location 'http://localhost:4000/v1/vector_stores/vs_123/files' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer sk-1234' \
--data '{
"file_id": "file_abc"
}'
Get Started with Vector Stores
New Providers and Endpoints
New Providers
| Provider | Supported Endpoints | Description |
|---|---|---|
| RunwayML | /v1/videos, /v1/images/generations, /v1/audio/speech | Gen-4 video generation, image generation, and text-to-speech |
New LLM API Endpoints
| Endpoint | Method | Description | Documentation |
|---|---|---|---|
/v1/vector_stores/{vector_store_id}/files | POST | Create vector store file | Docs |
/v1/vector_stores/{vector_store_id}/files | GET | List vector store files | Docs |
/v1/vector_stores/{vector_store_id}/files/{file_id} | GET | Retrieve vector store file | Docs |
/v1/vector_stores/{vector_store_id}/files/{file_id}/content | GET | Retrieve file content | Docs |
/v1/vector_stores/{vector_store_id}/files/{file_id} | DELETE | Delete vector store file | Docs |
/v1/vector_stores/{vector_store_id} | DELETE | Delete vector store | Docs |
New Models / Updated Models
New Model Support
| Provider | Model | Context Window | Input ($/1M tokens) | Output ($/1M tokens) | Features |
|---|---|---|---|---|---|
| OpenAI | gpt-5.1 | 272K | $1.25 | $10.00 | Reasoning, vision, PDF input, responses API |
| OpenAI | gpt-5.1-2025-11-13 | 272K | $1.25 | $10.00 | Reasoning, vision, PDF input, responses API |
| OpenAI | gpt-5.1-chat-latest | 128K | $1.25 | $10.00 | Reasoning, vision, PDF input |
| OpenAI | gpt-5.1-codex | 272K | $1.25 | $10.00 | Responses API, reasoning, vision |
| OpenAI | gpt-5.1-codex-mini | 272K | $0.25 | $2.00 | Responses API, reasoning, vision |
| Moonshot | moonshot/kimi-k2-thinking | 262K | $0.60 | $2.50 | Function calling, web search, reasoning |
| Mistral | mistral/magistral-medium-2509 | 40K | $2.00 | $5.00 | Reasoning, function calling |
| Vertex AI | vertex_ai/moonshotai/kimi-k2-thinking-maas | 256K | $0.60 | $2.50 | Function calling, web search |
| OpenRouter | openrouter/deepseek/deepseek-v3.2-exp | 164K | $0.20 | $0.40 | Function calling, prompt caching |
| OpenRouter | openrouter/minimax/minimax-m2 | 205K | $0.26 | $1.02 | Function calling, reasoning |
| OpenRouter | openrouter/z-ai/glm-4.6 | 203K | $0.40 | $1.75 | Function calling, reasoning |
| OpenRouter | openrouter/z-ai/glm-4.6:exacto | 203K | $0.45 | $1.90 | Function calling, reasoning |
| Voyage | voyage/voyage-3.5 | 32K | $0.06 | - | Embeddings |
| Voyage | voyage/voyage-3.5-lite | 32K | $0.02 | - | Embeddings |
Video Generation Models
| Provider | Model | Cost Per Second | Resolutions | Features |
|---|---|---|---|---|
| RunwayML | runwayml/gen4_turbo | $0.05 | 1280x720, 720x1280 | Text + image to video |
| RunwayML | runwayml/gen4_aleph | $0.15 | 1280x720, 720x1280 | Text + image to video |
| RunwayML | runwayml/gen3a_turbo | $0.05 | 1280x720, 720x1280 | Text + image to video |
Image Generation Models
| Provider | Model | Cost Per Image | Resolutions | Features |
|---|---|---|---|---|
| RunwayML | runwayml/gen4_image | $0.05 | 1280x720, 1920x1080 | Text + image to image |
| RunwayML | runwayml/gen4_image_turbo | $0.02 | 1280x720, 1920x1080 | Text + image to image |
| Fal.ai | fal_ai/fal-ai/flux-pro/v1.1 | $0.04/image | - | Image generation |
| Fal.ai | fal_ai/fal-ai/flux/schnell | $0.003/image | - | Fast image generation |
| Fal.ai | fal_ai/fal-ai/bytedance/seedream/v3/text-to-image | $0.03/image | - | Image generation |
| Fal.ai | fal_ai/fal-ai/bytedance/dreamina/v3.1/text-to-image | $0.03/image | - | Image generation |
| Fal.ai | fal_ai/fal-ai/ideogram/v3 | $0.06/image | - | Image generation |
| Fal.ai | fal_ai/fal-ai/imagen4/preview/fast | $0.02/image | - | Fast image generation |
| Fal.ai | fal_ai/fal-ai/imagen4/preview/ultra | $0.06/image | - | High-quality image generation |
Audio Models
| Provider | Model | Cost | Features |
|---|---|---|---|
| RunwayML | runwayml/eleven_multilingual_v2 | $0.0003/char | Text-to-speech |
Features
-
Gemini (Google AI Studio + Vertex AI)
- Add support for
reasoning_effort='none'for Gemini models - PR #16548 - Add all Gemini image models support in image generation - PR #16526
- Add Gemini image edit support - PR #16430
- Fix preserve non-ASCII characters in function call arguments - PR #16550
- Fix Gemini conversation format issue with MCP auto-execution - PR #16592
- Add support for
-
- Add support for filtering knowledge base queries - PR #16543
- Ensure correct
aws_regionis used when provided dynamically for embeddings - PR #16547 - Add support for custom KMS encryption keys in Bedrock Batch operations - PR #16662
- Add bearer token authentication support for AgentCore - PR #16556
- Fix AgentCore SSE stream iterator to async for proper streaming support - PR #16293
-
- Fix Magistral streaming to emit reasoning chunks - PR #16434
-
- Add Kimi K2 thinking model support - PR #16445
-
- Fix SambaNova API rejecting requests when message content is passed as a list format - PR #16612
-
- Fix improve Azure auth parameter handling for None values - PR #14436
-
- Fix parse failed chunks for Groq - PR #16595
-
- Add Voyage 3.5 and 3.5-lite embeddings pricing and doc update - PR #16641
Bug Fixes
- General
- Fix sanitize null token usage in OpenAI-compatible responses - PR #16493
- Fix apply provided timeout value to ClientTimeout.total - PR #16395
- Fix raising wrong 429 error on wrong exception - PR #16482
- Add new models, delete repeat models, update pricing - PR #16491
- Update model logging format for custom LLM provider - PR #16485
LLM API Endpoints
New Endpoints
- GET /providers
- Add GET list of providers endpoint - PR #16432
Features
-
- Allow internal users to access video generation routes - PR #16472
-
- Vector store files stable release with complete CRUD operations - PR #16643
POST /v1/vector_stores/{vector_store_id}/files- Create vector store fileGET /v1/vector_stores/{vector_store_id}/files- List vector store filesGET /v1/vector_stores/{vector_store_id}/files/{file_id}- Retrieve vector store fileGET /v1/vector_stores/{vector_store_id}/files/{file_id}/content- Retrieve file contentDELETE /v1/vector_stores/{vector_store_id}/files/{file_id}- Delete vector store fileDELETE /v1/vector_stores/{vector_store_id}- Delete vector store
- Ensure users can access
search_resultsfor both stream + non-stream response - PR #16459
- Vector store files stable release with complete CRUD operations - PR #16643
Bugs
-
- Fix use GET for
/v1/videos/{video_id}/content- PR #16672
- Fix use GET for
-
General
- Fix remove generic exception handling - PR #16599
Management Endpoints / UI
Features
-
Proxy CLI Auth
- Fix remove strict master_key check in add_deployment - PR #16453
-
Virtual Keys
-
Models + Endpoints
- UI - Add LiteLLM Params to Edit Model - PR #16496
- UI - Add Model use backend data - PR #16664
- UI - Remove Description Field from LLM Credentials - PR #16608
- UI - Add RunwayML on Admin UI supported models/providers - PR #16606
- Infra - Migrate Add Model Fields to Backend - PR #16620
- Add API Endpoint for creating model access group - PR #16663
-
Teams
-
Budgets
- UI - Move Budgets out of Experimental - PR #16544
-
Guardrails
-
Callbacks
-
Usage & Analytics
-
Health Check
- Add Langfuse OTEL and SQS to Health Check - PR #16514
-
General UI
- UI - Normalize table action columns appearance - PR #16657
- UI - Button Styles and Sizing in Settings Pages - PR #16600
- UI - SSO Modal Cosmetic Changes - PR #16554
- Fix UI logos loading with SERVER_ROOT_PATH - PR #16618
- Fix remove misleading 'Custom' option mention from OpenAI endpoint tooltips - PR #16622
-
SSO
- Ensure
rolefrom SSO provider is used when a user is inserted onto LiteLLM - PR #16794
- Ensure
Bugs
- Management Endpoints
- Fix inconsistent error responses in customer management endpoints - PR #16450
- Fix correct date range filtering in /spend/logs endpoint - PR #16443
- Fix /spend/logs/ui Access Control - PR #16446
- Add pagination for /spend/logs/session/ui endpoint - PR #16603
- Fix LiteLLM Usage shows key_hash - PR #16471
- Fix app_roles missing from jwt payload - PR #16448
Logging / Guardrail / Prompt Management Integrations
New Integration
- 🆕 Zscaler AI Guard
- Add Zscaler AI Guard hook for security policy enforcement - PR #15691
Logging
-
- Fix handle null usage values to prevent validation errors - PR #16396
-
- Fix updated spend would not be sent to CloudZero - PR #16201
Guardrails
- IBM Detector
- Ensure detector-id is passed as header to IBM detector server - PR #16649
Prompt Management
- Custom Prompt Management
- Add SDK focused examples for custom prompt management - PR #16441
Spend Tracking, Budgets and Rate Limiting
- End User Budgets
- Allow pointing max_end_user budget to an id, so the default ID applies to all end users - PR #16456
MCP Gateway
- Configuration
- Add dynamic OAuth2 metadata discovery for MCP servers - PR #16676
- Fix allow tool call even when server name prefix is missing - PR #16425
- Fix exclude unauthorized MCP servers from allowed server list - PR #16551
- Fix unable to delete MCP server from permission settings - PR #16407
- Fix avoid crashing when MCP server record lacks credentials - PR #16601
Agents
- Agent Registration (A2A Spec)
- Support agent registration + discovery following Agent-to-Agent specification - PR #16615
Performance / Loadbalancing / Reliability improvements
-
Embeddings Performance
- Use router's O(1) lookup and shared sessions for embeddings - PR #16344
-
Router Reliability
- Support default fallbacks for unknown models - PR #16419
-
Callback Management
- Add atexit handlers to flush callbacks for async completions - PR #16487
General Proxy Improvements
- Configuration Management
- Fix update model_cost_map_url to use environment variable - PR #16429
Documentation Updates
-
Provider Documentation
-
API Documentation
-
General Documentation
New Contributors
- @artplan1 made their first contribution in PR #16423
- @JehandadK made their first contribution in PR #16472
- @vmiscenko made their first contribution in PR #16453
- @mcowger made their first contribution in PR #16429
- @yellowsubmarine372 made their first contribution in PR #16395
- @Hebruwu made their first contribution in PR #16201
- @jwang-gif made their first contribution in PR #15691
- @AnthonyMonaco made their first contribution in PR #16502
- @andrewm4894 made their first contribution in PR #16487
- @f14-bertolotti made their first contribution in PR #16485
- @busla made their first contribution in PR #16293
- @MightyGoldenOctopus made their first contribution in PR #16537
- @ultmaster made their first contribution in PR #14436
- @bchrobot made their first contribution in PR #16542
- @sep-grindr made their first contribution in PR #16622
- @pnookala-godaddy made their first contribution in PR #16607
- @dtunikov made their first contribution in PR #16592
- @lukapecnik made their first contribution in PR #16648
- @jyeros made their first contribution in PR #16618
Full Changelog
View complete changelog on GitHub