v1.75.5-stable - Redis latency improvements


Deploy this version
- Docker
- Pip
docker run \
-e STORE_MODEL_IN_DB=True \
-p 4000:4000 \
docker.litellm.ai/berriai/litellm:v1.75.5-stable
pip install litellm==1.75.5.post2
Key Highlights
- Redis - Latency Improvements - Reduces P99 latency by 50% with Redis enabled.
- Responses API Session Management - Support for managing responses API sessions with images.
- Oracle Cloud Infrastructure - New LLM provider for calling models on Oracle Cloud Infrastructure.
- Digital Ocean's Gradient AI - New LLM provider for calling models on Digital Ocean's Gradient AI platform.
Risk of Upgrade
If you build the proxy from the pip package, you should hold off on upgrading. This version makes prisma migrate deploy our default for managing the DB. This is safer, as it doesn't reset the DB, but it requires a manual prisma generate step.
Users of our Docker image, are not affected by this change.
Redis Latency Improvements
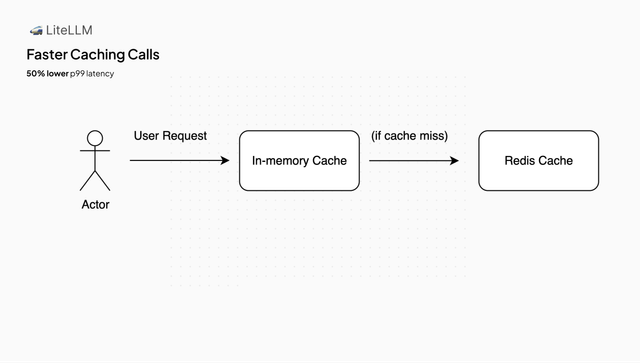
This release adds in-memory caching for Redis requests, enabling faster response times in high-traffic. Now, LiteLLM instances will check their in-memory cache for a cache hit, before checking Redis. This reduces caching-related latency from 100ms for LLM API calls to sub-1ms, on cache hits.
Responses API Session Management w/ Images
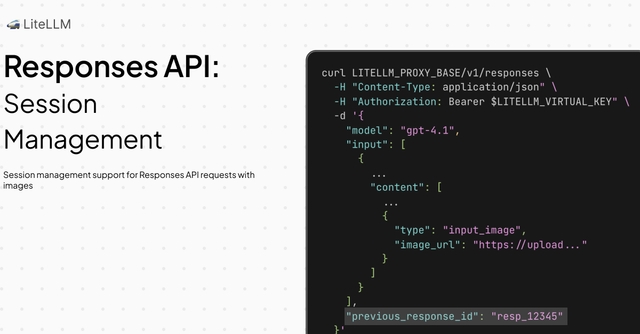
LiteLLM now supports session management for Responses API requests with images. This is great for use-cases like chatbots, that are using the Responses API to track the state of a conversation. LiteLLM session management works across ALL LLM API's (including Anthropic, Bedrock, OpenAI, etc). LiteLLM session management works by storing the request and response content in an s3 bucket, you can specify.
New Models / Updated Models
New Model Support
| Provider | Model | Context Window | Input ($/1M tokens) | Output ($/1M tokens) |
|---|---|---|---|---|
| Bedrock | bedrock/us.anthropic.claude-opus-4-1-20250805-v1:0 | 200k | $15 | $75 |
| Bedrock | bedrock/openai.gpt-oss-20b-1:0 | 200k | 0.07 | 0.3 |
| Bedrock | bedrock/openai.gpt-oss-120b-1:0 | 200k | 0.15 | 0.6 |
| Fireworks AI | fireworks_ai/accounts/fireworks/models/glm-4p5 | 128k | 0.55 | 2.19 |
| Fireworks AI | fireworks_ai/accounts/fireworks/models/glm-4p5-air | 128k | 0.22 | 0.88 |
| Fireworks AI | fireworks_ai/accounts/fireworks/models/gpt-oss-120b | 131072 | 0.15 | 0.6 |
| Fireworks AI | fireworks_ai/accounts/fireworks/models/gpt-oss-20b | 131072 | 0.05 | 0.2 |
| Groq | groq/openai/gpt-oss-20b | 131072 | 0.1 | 0.5 |
| Groq | groq/openai/gpt-oss-120b | 131072 | 0.15 | 0.75 |
| OpenAI | openai/gpt-5 | 400k | 1.25 | 10 |
| OpenAI | openai/gpt-5-2025-08-07 | 400k | 1.25 | 10 |
| OpenAI | openai/gpt-5-mini | 400k | 0.25 | 2 |
| OpenAI | openai/gpt-5-mini-2025-08-07 | 400k | 0.25 | 2 |
| OpenAI | openai/gpt-5-nano | 400k | 0.05 | 0.4 |
| OpenAI | openai/gpt-5-nano-2025-08-07 | 400k | 0.05 | 0.4 |
| OpenAI | openai/gpt-5-chat | 400k | 1.25 | 10 |
| OpenAI | openai/gpt-5-chat-latest | 400k | 1.25 | 10 |
| Azure | azure/gpt-5 | 400k | 1.25 | 10 |
| Azure | azure/gpt-5-2025-08-07 | 400k | 1.25 | 10 |
| Azure | azure/gpt-5-mini | 400k | 0.25 | 2 |
| Azure | azure/gpt-5-mini-2025-08-07 | 400k | 0.25 | 2 |
| Azure | azure/gpt-5-nano-2025-08-07 | 400k | 0.05 | 0.4 |
| Azure | azure/gpt-5-nano | 400k | 0.05 | 0.4 |
| Azure | azure/gpt-5-chat | 400k | 1.25 | 10 |
| Azure | azure/gpt-5-chat-latest | 400k | 1.25 | 10 |
Features
- OCI
- New LLM provider - PR #13206
- JinaAI
- support multimodal embedding models - PR #13181
- GPT-5 (OpenAI/Azure)
- Anthropic
- Add claude-opus-4-1 on model cost map - PR #13384
- OpenRouter
- Add gpt-oss to model cost map - PR #13442
- Cerebras
- Add gpt-oss to model cost map - PR #13442
- Azure
- Support drop params for ‘temperature’ on o-series models - PR #13353
- GradientAI
- New LLM Provider - PR #12169
Bugs
LLM API Endpoints
Features
/responses
Bugs
/chat/completions/responses/v1/messages- Added litellm claude code count tokens - PR #13261
/vector_stores- Fix create/search vector store errors - PR #13285
MCP Gateway
Features
Bugs
- Fix auth on UI for bearer token servers - PR #13312
- allow access group on mcp tool retrieval - PR #13425
Management Endpoints / UI
Features
- Teams
- Add team deletion check for teams with keys - PR #12953
- Models
- Keys
- Navbar
- Add logo customization for LiteLLM admin UI - PR #12958
- Logs
- Add token breakdowns on logs + session page - PR #13357
- Usage
- Ensure Usage Page loads after the DB has large entries - PR #13400
- Test Key Page
- allow uploading images for /chat/completions and /responses - PR #13445
- MCP
- Add auth tokens to local storage auth - PR #13473
Bugs
- Custom Root Path
- Fix login route when SSO is enabled - PR #13267
- Customers/End-users
- Allow calling /v1/models when end user over budget - allows model listing to work on OpenWebUI when customer over budget - PR #13320
- Teams
- Remove user - team membership, when user removed from team - PR #13433
- Errors
- Bubble up network errors to user for Logging and Alerts page - PR #13427
- Model Hub
- Show pricing for azure models, when base model is set - PR #13418
Logging / Guardrail Integrations
Features
- Bedrock Guardrails
- Redacted sensitive information in bedrock guardrails error message - PR #13356
- Standard Logging Payload
- Fix ‘can’t register atextexit’ bug - PR #13436
Bugs
- Braintrust
- Allow setting of braintrust callback base url - PR #13368
- OTEL
- Track pre_call hook latency - PR #13362
Performance / Loadbalancing / Reliability improvements
Features
- Team-BYOK models
- Add wildcard model support - PR #13278
- Caching
- GCP IAM auth support for caching - PR #13275
- Latency
- reduce p99 latency w/ redis enabled by 50% - only updates model usage if tpm/rpm limits set - PR #13362
General Proxy Improvements
Features
- Models
- Support /v1/models/{model_id} retrieval - PR #13268
- Multi-instance
- Ensure disable_llm_api_endpoints works - PR #13278
- Logs
- Add apscheduler log suppress - PR #13299
- Helm
- Add labels to migrations job template - PR #13343 s/o @unique-jakub
Bugs
- Non-root image
- Fix non-root image for migration - PR #13379
- Get Routes
- Load get routes when using fastapi-offline - PR #13466
- Health checks
- Generate unique trace IDs for Langfuse health checks - PR #13468
- Swagger
- Allow using Swagger for /chat/completions - PR #13469
- Auth
- Fix JWTs access not working with model access groups - PR #13474
New Contributors
- @bbartels made their first contribution in https://github.com/BerriAI/litellm/pull/13244
- @breno-aumo made their first contribution in https://github.com/BerriAI/litellm/pull/13206
- @pascalwhoop made their first contribution in https://github.com/BerriAI/litellm/pull/13122
- @ZPerling made their first contribution in https://github.com/BerriAI/litellm/pull/13045
- @zjx20 made their first contribution in https://github.com/BerriAI/litellm/pull/13181
- @edwarddamato made their first contribution in https://github.com/BerriAI/litellm/pull/13368
- @msannan2 made their first contribution in https://github.com/BerriAI/litellm/pull/12169