v1.86.0rc1 - Weighted-Routing Failover, Native Web-Search Citations & OTel-Standard Tracing
Deploy this version
- Docker
- Pip
docker run \
-e STORE_MODEL_IN_DB=True \
-p 4000:4000 \
docker.litellm.ai/berriai/litellm:1.86.0-rc.1
pip install litellm==1.86.0rc1
Key Highlights
- Weighted-Routing Failover — on a deployment failure, the router now retries the same model group on a different deployment (e.g. another Azure region) while the initial pick still respects configured weights, behind a router-level flag.
- Native web-search citations for Anthropic clients — LiteLLM now emits native
web_search_tool_resultblocks so Claude Desktop / Cowork render web-search citations correctly. - OTel-standard server-span attributes — the proxy SERVER span now carries
http.response.status_code,http.route,url.path, andlitellm.preprocessing.duration_ms, plus an opt-in for the experimental OTEL GenAI semantic conventions. - Componentized deployment — additive scaffold + Helm chart to split the monolithic proxy into independently scalable
gateway,backend, anduiservices. - Critical rate-limit regression fixed — the v3 limiter was leaking internal reservation keys into the upstream provider body, breaking every virtual key with a
tpm_limit/rpm_limitset.
Claude Code compatibility coverage
We expanded the set of Claude Code features that LiteLLM automatically tests against daily, and added a Known Issues section to the Claude Code compatibility doc so customers can see which combinations are red, and why, before hitting them in production.
This is a direct response to customer feedback on stability and regressions. The matrix is backed by a rigorous end-to-end suite that hits real provider endpoints with no mocking. The suite re-runs every day and the doc renders the latest LiteLLM stable against the latest Claude Code version.
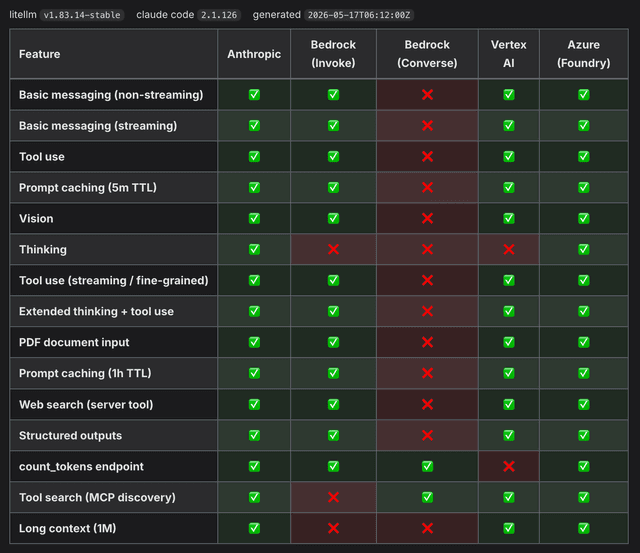
Today's coverage sits at 76% across Anthropic, Bedrock Invoke, Bedrock Converse, Vertex AI, and Azure Foundry. Over the next week we plan to bring this to 90%. Coming soon, the same suite will gate PRs: any cell flipping green to red will fail the check and block merges into staging, making it much harder for code that breaks Claude Code to land in the next release.
New Models / Updated Models
New Model Support
| Provider | Model | Context Window | Input ($/1M tokens) | Output ($/1M tokens) | Features |
|---|---|---|---|---|---|
| Bedrock | jp.anthropic.claude-sonnet-4-6 | 1,000,000 | $3.30 | $16.50 | Prompt caching, reasoning, vision, function calling, PDF input, computer use |
| Azure AI | azure_ai/gpt-5.4 | 1,050,000 | $2.50 | $15.00 | Reasoning, vision, web search, function calling, prompt caching, service tier |
| Azure AI | azure_ai/gpt-5.4-pro | 1,050,000 | $30.00 | $180.00 | Responses-mode, reasoning, vision, web search, prompt caching |
| Azure AI | azure_ai/gpt-5.4-mini | 400,000 | $0.75 | $4.50 | Reasoning, vision, web search, function calling, prompt caching |
| Azure AI | azure_ai/gpt-5.4-nano | 400,000 | $0.20 | $1.25 | Reasoning, vision, web search, function calling, prompt caching |
Each Azure AI GPT-5.4 model also ships a dated snapshot alias (gpt-5.4-2026-03-05, gpt-5.4-pro-2026-03-05, gpt-5.4-mini-2026-03-17, gpt-5.4-nano-2026-03-17) — 9 catalog entries total. All GPT-5.4 entries include tiered (>272k) and priority pricing.
Features
- Azure AI
- Add Azure AI Foundry GPT-5.4 model metadata (gpt-5.4 / pro / mini / nano + dated aliases) - PR #28030
- Bedrock
- Add
jp.cross-region inference profile forclaude-sonnet-4-6- PR #27976
- Add
Bug Fixes
- Bedrock
- bedrock-mantle: use
/anthropic/v1/messagespath for Mantle (Claude Mythos Preview) endpoint —/v1/messageswas 404ing every Mantle request - PR #27976
- bedrock-mantle: use
LLM API Endpoints
Features
- Anthropic Messages API (
/v1/messages)- Emit native
web_search_tool_resultblocks for Anthropic clients (Claude Desktop / Cowork citations) - PR #27886
- Emit native
- Vector Stores
- Fix vector store retrieve/list/update/delete when no completion model is set; merge URL query params into request data on those routes - PR #27929
Bugs
- Batch API
- Managed batches: convert raw provider
output_file_idto managed ID in theCheckBatchCostpoller soGET /files/{id}/contentresolves routing - PR #27984
- Managed batches: convert raw provider
Management Endpoints / UI
Bugs
- Auth / OAuth
- Allow allowlisted redirect URIs in OAuth setup - PR #27761
- Config
- Make
/config/updateenv-var encryption idempotent (fixes double-encryption on repeated updates) + endpoint-level regression test - PR #28022
- Make
- Models + Endpoints
- Sort BYOK models by their displayed name in
/v2/model/info- PR #28079
- Sort BYOK models by their displayed name in
AI Integrations
Logging
- OpenTelemetry
- OTel-standard attributes on the proxy SERVER span:
http.response.status_code,http.route,url.path,litellm.preprocessing.duration_ms- PR #28040 - Set
http.response.status_codeon the success SERVER span (not just error spans) - PR #28090 - Opt-in support for the experimental OTEL GenAI semantic conventions (
OTEL_SEMCONV_STABILITY_OPT_IN=gen_ai_latest_experimental); default behavior unchanged - PR #27418
- OTel-standard attributes on the proxy SERVER span:
Guardrails
- Lasso
- Add tool-calling support to LassoGuardrail (expands
tool_calls/role=toolinto Lassotool_use/tool_resultblocks; maps tool definitions) - PR #27648
- Add tool-calling support to LassoGuardrail (expands
- CrowdStrike AIDR
- Improve CrowdStrike AIDR input handling - PR #26658
Secret Managers
- General
- Import
get_secretat runtime to avoid an import-time ordering bug - PR #28014
- Import
Spend Tracking, Budgets and Rate Limiting
- Rate Limiting — Stop the v3 limiter from leaking internal reservation keys (
_litellm_rate_limit_descriptors,_litellm_tpm_reserved_*) into the upstream provider body; this regression broke every virtual key with atpm_limit/rpm_limit- PR #27913 - Budgets — Tighten budget field validation and add missing authorization checks on user self-update / key-generation paths - PR #27897
- Cost Tracking — Fix zero cost/usage on completed Vertex AI batch jobs (file content is now OpenAI-shaped post-#25627; old code read stale
usageMetadata.*) - PR #27912
MCP Gateway
- Delegate-auth PKCE bypass for internal (
available_on_public_internet: false) oauth2 interactive MCP servers — same anonymous PKCE path as public servers;client_credentialsexclusion unchanged - PR #27977 - Expose
delegate_auth_to_upstreamin theGET /v1/mcp/serverlist API (_build_mcp_server_tablewas dropping it, so the dashboard always showedfalse) - PR #27936
Performance / Loadbalancing / Reliability improvements
- Weighted-Routing Failover — on failure, retry the same model group on a different deployment while the initial pick respects configured weights; behind a router-level flag - PR #27980
- Chat-completions fast path — cache callback capabilities once instead of re-scanning
litellm.callbacksper request; skip streaming-iterator wrapping when no callback needs it - PR #27858 - Componentized deployment — additive
gateway/,backend/,ui/Dockerfiles + Helm chart (per-component Deployment/Service/HPA, no edits to existing modules) - PR #27557 - Terraform stacks — AWS ECS + GCP Cloud Run stacks for deploying the componentized gateway - PR #27673
General Proxy Improvements
Testing, CI & build hardening:
- VCR cache observability: classify cache verdicts, detect live calls, surface cost leaks, aggregate xdist worker stats; Bedrock hostname / RFC1918 fixes - PR #27795
- Reasoning-effort grid e2e regression suite (status classified by exception
status_code); Fireworks / Gemini tests mocked instead of live - PR #28036 - Modernize model references in CI tests and configs - PR #27856
- Codecov: flag uploads, enable carryforward, close coverage gaps;
--cov=./litellmpath resolution - PR #28028, PR #27960 - mutmut: enable
mutate_only_covered_linesto fit CI budget - PR #27910 - Remove unused GitHub Actions workflows and orphan files - PR #27957
- Preserve global Button/Tooltip mocks in per-file
@tremor/reactvi.mock(UI tests) - PR #27958 - Isolate
run_serverCLI tests from the Prisma DB-setup path - PR #28029 - Validate response fields against the Interaction schema - PR #28037
- De-flake
test_gemini_image_size_limit_exceeded- PR #28039 - Pin
openai==2.33.0inuv.lock- PR #28088
New Contributors
- @vladpolevoi made their first contribution in #27648
Full Changelog: https://github.com/BerriAI/litellm/compare/v1.85.0-rc.2...v1.86.0-rc.1
05/16/2026 (v1.86.0rc1)
- New Models / Updated Models: 2
- LLM API Endpoints: 3
- Management Endpoints / UI: 3
- AI Integrations (Logging / Guardrails / Secret Managers): 6
- Spend Tracking, Budgets and Rate Limiting: 3
- MCP Gateway: 3
- Performance / Loadbalancing / Reliability improvements: 4
- General Proxy Improvements (testing / CI / build): 12
- Documentation Updates: 0
Total: 36 PRs