Debugging a cost discrepancy
Cost discrepancies between LiteLLM and your provider bill usually come from one of three areas: token ingestion, the cost formula LiteLLM applies, or stale or incorrect pricing in the model map. This page walks through how to tell which case you are in.
Step 1: Pick a time range
Lock down a specific window where the discrepancy is visible.
- Use at least 7 days of data when you can.
- Prefer a window with stable usage so one-off spikes do not dominate the comparison.
- Set the same start and end time on both your provider dashboard and the LiteLLM UI.
Step 2: Confirm traffic only goes through LiteLLM
If any requests hit the provider directly (bypassing LiteLLM), the provider will show higher usage. That is expected, not a LiteLLM bug.
Before continuing, confirm:
- All clients use your LiteLLM proxy base URL.
- No SDK or script uses provider API keys against the provider directly for the models you are comparing.
- During the selected period, the models in question are only called via LiteLLM.
If you are unsure, filter the provider dashboard by the API key or IAM principal LiteLLM uses, rather than comparing to your whole account.
Step 3: Compare token categories
In the LiteLLM UI, open Model activity (under Usage analytics) so you can inspect spend and tokens per model.
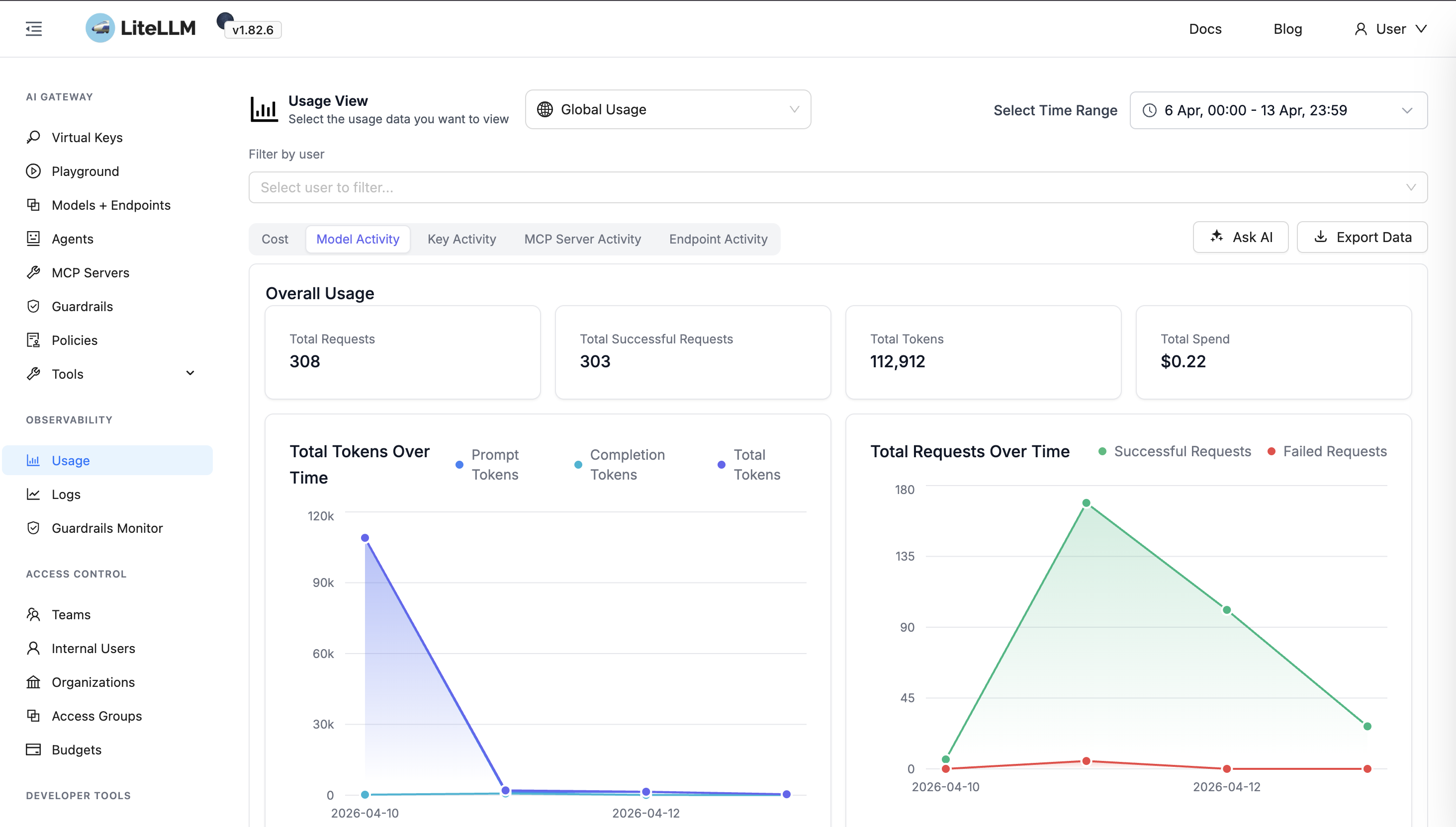
Scroll the Model list and select the model you are reconciling with your provider bill.
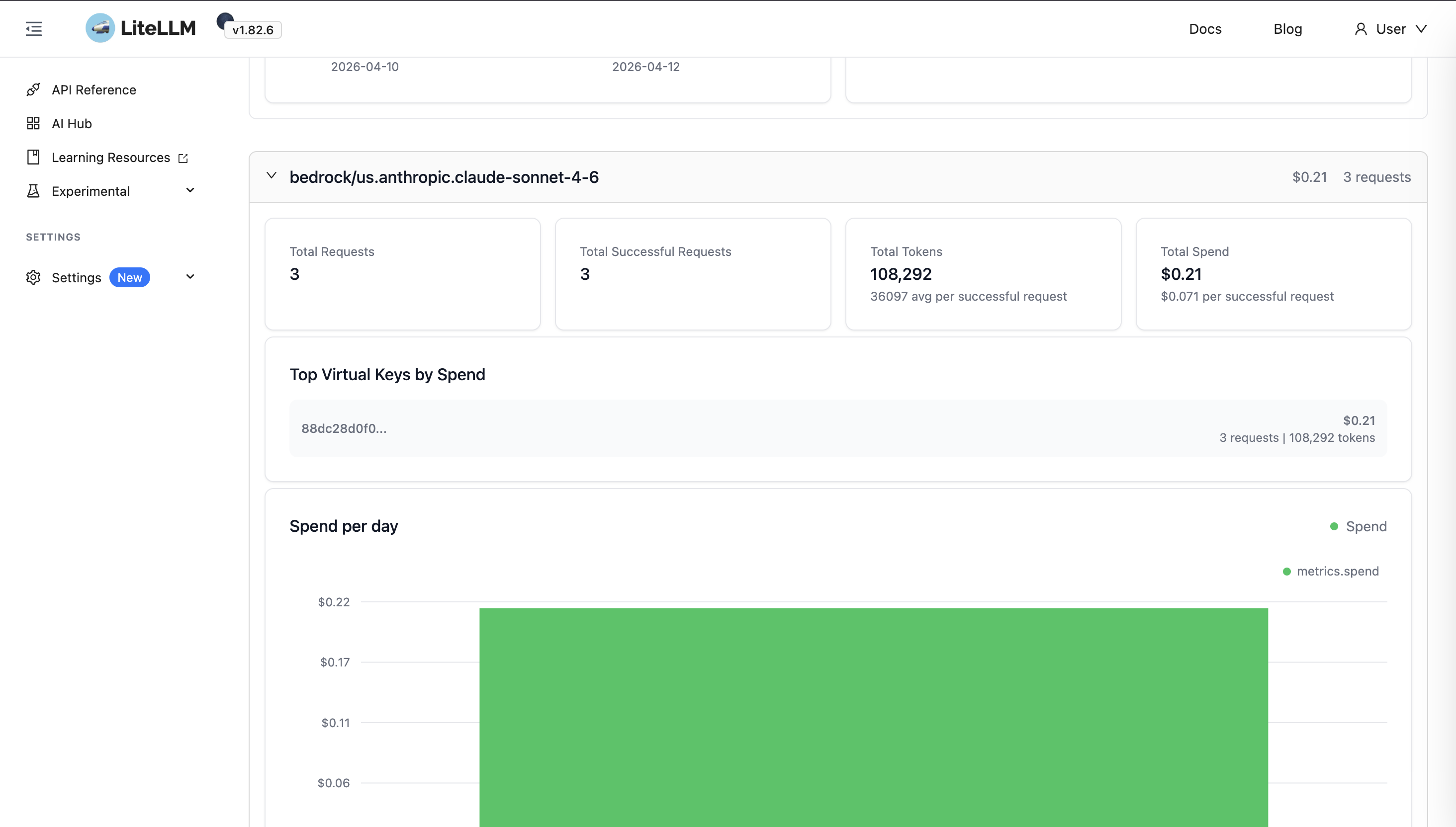
With the same time range on both sides, fill in:
| Category | LiteLLM | Provider | Delta |
|---|---|---|---|
| Total requests | — | — | — |
| Input tokens | — | — | — |
| Output tokens | — | — | — |
| Cache read tokens | — | — | — |
| Cache write tokens | — | — | — |
LiteLLM surfaces per-category token usage for the selected model—for example prompt, completion, and cache-related tokens.
Compare these figures with your provider’s usage view (for example AWS billing tools, Azure Monitor, or the OpenAI usage dashboard) for the same period.
Cache token reporting
- OpenAI: Cache read tokens are typically included inside the reported input token count.
- Anthropic: Cache read tokens are often reported separately from non-cached input tokens.
Compare the correct columns on each side so you are not treating “input” differently between dashboards.
Why use a 10% threshold?
Provider dashboards and LiteLLM do not bucket requests on identical timestamps. A call at 11:59 PM can land in different daily totals on each side. Token counts can also differ slightly due to rounding across SDKs and APIs. A delta under ~10% is often explained by boundary effects and rounding. A delta over ~10% usually means something is miscounted, dropped, or categorized differently.
Step 4: Follow the right path
Path A: Token quantity mismatch
If any category is off by more than about 10%, LiteLLM may not be ingesting that category correctly (or the provider dashboard is categorizing tokens differently—recheck Step 3 first).
What to send the LiteLLM team:
- Screenshots of both dashboards with the date range visible.
- Which category is off (input, output, cache reads, cache writes, or request count).
- Endpoints used (for example
/chat/completions,/responses,/embeddings). - Model names as sent in the request (for example
anthropic.claude-opus-4-5,gpt-4o).
For maintainers debugging ingestion
- Start the proxy with verbose logging, for example:
litellm --config config.yaml --detailed_debug - Reproduce a single request with the reported endpoint and model.
- Inspect the raw
usageobject in each streamed chunk (if streaming) or in the final response body. - Compare that to the standard logging object (or the UI request log for that call).
- Any gap between raw provider usage and what LiteLLM logs or aggregates is where ingestion may be wrong.
Path B: Quantities match but cost is wrong
If token and request counts agree within ~10% but dollar amounts differ, focus on how cost is computed.
B1: Formula issue
Manually compute expected cost using the provider’s token breakdown and published rates (per million tokens or per token).
Add other billed dimensions your provider applies (for example cache creation, audio, or tier surcharges). If your hand calculation matches the provider bill but not LiteLLM, the implementation in LiteLLM for that provider or modality may be wrong.
B2: Model map issue
If the formula structure matches how the provider bills, the values in LiteLLM’s model map may be stale or incorrect. Cross-check:
model_prices_and_context_window.json- The provider’s current public pricing
Inspect input_cost_per_token, output_cost_per_token, and any cache-related pricing fields for your exact model id (including provider prefix).
For maintainers
- Take authoritative token quantities from the user’s provider report.
- Derive the formula that reproduces the provider’s line item.
- Diff that against LiteLLM’s cost path for the same provider and response shape.
- If the formula matches but numbers differ, update pricing in
model_prices_and_context_window.json(and follow the project’s sync / backup rules for that file). - If the formula in code is wrong, fix the calculation and add a regression test using the user’s token breakdown.
Still stuck?
- Open a GitHub issue on BerriAI/litellm with your Step 3 comparison table, endpoints, and model names.
On the issue, it helps to clarify:
- Reproducible on demand or intermittent?
- Single model or many?
- Steady over time, or starting from a specific release date or config change?
For LiteLLM maintainers
If Path A and Path B do not close the case after triage, you should reach out and schedule a call with the customer (support or engineering), with the Step 3 table and screenshots—before treating the issue.
Checklist
□ Same time range on both dashboards
□ Confirmed no direct-to-provider traffic for those models
□ Compared: requests, input tokens, output tokens, cache tokens
□ Noted cache reporting differences (OpenAI vs Anthropic, and so on)
□ If > ~10% delta on quantities → Path A: report with screenshots, endpoints, model names
□ If quantities match → Path B: verify formula (B1) and model map pricing (B2)
□ If neither path fits → open a GitHub issue.