LiteLLM Proxy - 1K RPS Load test on locust
Tutorial on how to get to 1K+ RPS with LiteLLM Proxy on locust
Pre-Testing Checklist
- Ensure you're using the latest
-stableversion of litellm - Ensure you're following ALL best practices for production
- Locust - Ensure you're Locust instance can create 1K+ requests per second
- 👉 You can use our maintained locust instance here
- If you're self hosting locust
- Use this machine specification for running litellm proxy
- Enterprise LiteLLM - Use
prometheusas a callback in yourproxy_config.yamlto get metrics on your load test Setlitellm_settings.callbacksto monitor success/failures/all types of errorslitellm_settings:
callbacks: ["prometheus"] # Enterprise LiteLLM Only - use prometheus to get metrics on your load test
Use this config for testing:
Note: we're currently migrating to aiohttp which has 10x higher throughput. We recommend using the openai/ provider for load testing.
You can use our hosted fake endpoint or self-host your own using github.com/BerriAI/example_openai_endpoint.
model_list:
- model_name: "fake-openai-endpoint"
litellm_params:
model: openai/any
api_base: https://exampleopenaiendpoint-production.up.railway.app/ # or your self-hosted endpoint
api_key: "test"
Load Test - Fake OpenAI Endpoint
Expected Performance
| Metric | Value |
|---|---|
| Requests per Second | 1174+ |
| Median Response Time | 96ms |
| Average Response Time | 142.18ms |
Run Test
- Add
fake-openai-endpointto your proxy config.yaml and start your litellm proxy litellm provides a hostedfake-openai-endpointyou can load test against
model_list:
- model_name: fake-openai-endpoint
litellm_params:
model: openai/fake
api_key: fake-key
api_base: https://exampleopenaiendpoint-production.up.railway.app/
litellm_settings:
callbacks: ["prometheus"] # Enterprise LiteLLM Only - use prometheus to get metrics on your load test
-
uv add locust -
Create a file called
locustfile.pyon your local machine. Copy the contents from the litellm load test located here -
Start locust Run
locustin the same directory as yourlocustfile.pyfrom step 2
locust -f locustfile.py --processes 4
- Run Load test on locust
Head to the locust UI on http://0.0.0.0:8089
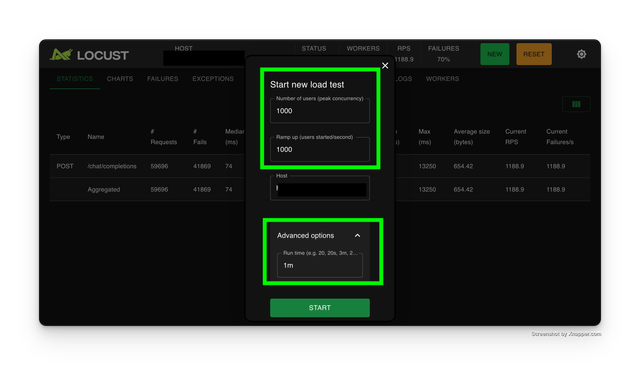
Set Users=1000, Ramp Up Users=1000, Host=Base URL of your LiteLLM Proxy
- Expected results
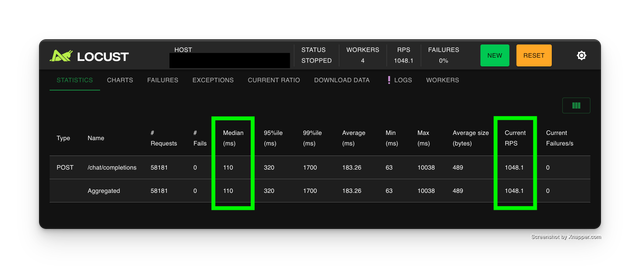
Load test - Endpoints with Rate Limits
Run a load test on 2 LLM deployments each with 10K RPM Quota. Expect to see ~20K RPM
Expected Performance
- We expect to see 20,000+ successful responses in 1 minute
- The remaining requests fail because the endpoint exceeds it's 10K RPM quota limit - from the LLM API provider
| Metric | Value |
|---|---|
| Successful Responses in 1 minute | 20,000+ |
| Requests per Second | ~1170+ |
| Median Response Time | 70ms |
| Average Response Time | 640.18ms |
Run Test
- Add 2
gemini-visiondeployments on your config.yaml. Each deployment can handle 10K RPM. (We setup a fake endpoint with a rate limit of 1000 RPM on the/v1/projects/bad-adroit-crowroute below )
All requests with model="gemini-vision" will be load balanced equally across the 2 deployments.
model_list:
- model_name: gemini-vision
litellm_params:
model: vertex_ai/gemini-1.0-pro-vision-001
api_base: https://exampleopenaiendpoint-production.up.railway.app/v1/projects/bad-adroit-crow-413218/locations/us-central1/publishers/google/models/gemini-1.0-pro-vision-001
vertex_project: "adroit-crow-413218"
vertex_location: "us-central1"
vertex_credentials: /etc/secrets/adroit_crow.json
- model_name: gemini-vision
litellm_params:
model: vertex_ai/gemini-1.0-pro-vision-001
api_base: https://exampleopenaiendpoint-production-c715.up.railway.app/v1/projects/bad-adroit-crow-413218/locations/us-central1/publishers/google/models/gemini-1.0-pro-vision-001
vertex_project: "adroit-crow-413218"
vertex_location: "us-central1"
vertex_credentials: /etc/secrets/adroit_crow.json
litellm_settings:
callbacks: ["prometheus"] # Enterprise LiteLLM Only - use prometheus to get metrics on your load test
-
uv add locust -
Create a file called
locustfile.pyon your local machine. Copy the contents from the litellm load test located here -
Start locust Run
locustin the same directory as yourlocustfile.pyfrom step 2
locust -f locustfile.py --processes 4 -t 60
- Run Load test on locust
Head to the locust UI on http://0.0.0.0:8089 and use the following settings
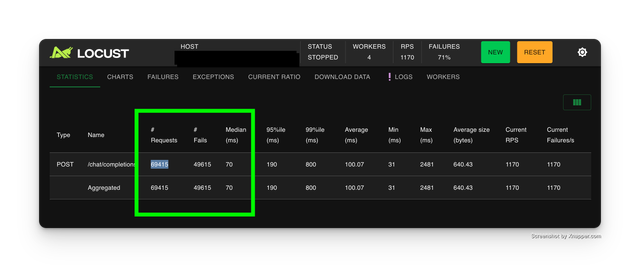
- Expected results
- Successful responses in 1 minute = 19,800 = (69415 - 49615)
- Requests per second = 1170
- Median response time = 70ms
- Average response time = 640ms
Prometheus Metrics for debugging load tests
Use the following prometheus metrics to debug your load tests / failures
| Metric Name | Description |
|---|---|
litellm_deployment_failure_responses | Total number of failed LLM API calls for a specific LLM deployment. Labels: "requested_model", "litellm_model_name", "model_id", "api_base", "api_provider", "hashed_api_key", "api_key_alias", "team", "team_alias", "exception_status", "exception_class" |
litellm_deployment_cooled_down | Number of times a deployment has been cooled down by LiteLLM load balancing logic. Labels: "litellm_model_name", "model_id", "api_base", "api_provider", "exception_status" |
Machine Specifications for Running Locust
| Metric | Value |
|---|---|
locust --processes 4 | 4 |
vCPUs on Load Testing Machine | 2.0 vCPUs |
Memory on Load Testing Machine | 450 MB |
Replicas of Load Testing Machine | 1 |
Machine Specifications for Running LiteLLM Proxy
👉 Number of Replicas of LiteLLM Proxy=4 for getting 1K+ RPS
| Service | Spec | CPUs | Memory | Architecture | Version |
|---|---|---|---|---|---|
| Server | t2.large. | 2vCPUs | 8GB | x86 |
Locust file used for testing
import os
import uuid
from locust import HttpUser, task, between
class MyUser(HttpUser):
wait_time = between(0.5, 1) # Random wait time between requests
@task(100)
def litellm_completion(self):
# no cache hits with this
payload = {
"model": "fake-openai-endpoint",
"messages": [{"role": "user", "content": f"{uuid.uuid4()} This is a test there will be no cache hits and we'll fill up the context" * 150 }],
"user": "my-new-end-user-1"
}
response = self.client.post("chat/completions", json=payload)
if response.status_code != 200:
# log the errors in error.txt
with open("error.txt", "a") as error_log:
error_log.write(response.text + "\n")
def on_start(self):
self.api_key = os.getenv('API_KEY', 'sk-1234')
self.client.headers.update({'Authorization': f'Bearer {self.api_key}'})