Deploy to Cloud (AWS, GCP, Azure)
Step-by-step guides for running LiteLLM proxy in production on AWS, Google Cloud, or Azure. There are two supported paths. If you run Kubernetes, deploy with Helm on EKS, GKE, or AKS; the install is the same on every cloud, only the data stores and ingress differ. If you do not run Kubernetes, AWS and GCP have official Terraform modules that stand up the entire stack; Azure has no Terraform module, so AKS with Helm is the supported path there.
Architecture
LiteLLM provides two deployment modes:
- Monolithic: one
litellmimage serves LLM traffic, management APIs, and the UI. This is what thelitellm-helmchart runs, and the simplest to operate. - Microservices: a
gateway(LLM traffic, port 4000),backend(management APIs and UI backend, port 4001), andui(port 3000), each deployed and scaled independently. This is what the componentizedlitellmchart and both Terraform modules run; see Microservices Helm for the full reference.
The supporting infrastructure is identical in either mode:
| Component | Purpose | Notes |
|---|---|---|
| LiteLLM services | One proxy deployment (monolithic) or gateway + backend + ui (microservices) | Stateless; run 2+ replicas behind a load balancer |
| PostgreSQL | Keys, teams, users, spend logs, config | Required for the proxy's auth and tracking features |
| Redis | Rate limiting, router state, caching across instances | Required once you run more than one instance |
| Migrations job | Applies schema migrations against Postgres | Runs once per upgrade; proxy instances set DISABLE_SCHEMA_UPDATE=true |
Core configuration
DATABASE_URL="postgresql://user:password@host:5432/litellm"
LITELLM_MASTER_KEY="sk-..." # admin key for the proxy
LITELLM_SALT_KEY="sk-..." # encrypts provider credentials stored in the DB. Set once, never change it
DISABLE_SCHEMA_UPDATE="true" # proxy instances never run migrations; the migrations job does
STORE_MODEL_IN_DB="True" # manage models from the Admin UI instead of config files
LITELLM_SALT_KEY cannot be rotated after you add models: it encrypts the provider credentials stored in your database, and changing it makes them unreadable. Generate a strong random value and store both keys in your cloud's secret manager.
Official images are published to ghcr.io/berriai and mirrored at docker.litellm.ai/berriai. Use ghcr.io/berriai/litellm-database for monolithic deployments with Postgres (it bundles the Prisma toolchain), and pin a version tag rather than latest or a moving tag, so rollbacks are deterministic.
Provision the data stores
The Helm path needs a PostgreSQL database and a Redis reachable from your cluster. Use the managed services:
- AWS
- Google Cloud
- Azure
Provision RDS PostgreSQL and ElastiCache Redis in the same VPC as your EKS cluster, with security groups permitting the cluster's nodes on ports 5432 and 6379.
Provision Cloud SQL PostgreSQL and Memorystore Redis with private IPs on the VPC your GKE cluster uses (Cloud SQL needs Private Services Access). Use the instances' private IPs as the endpoints below.
az group create --name litellm-prod --location eastus
az aks create --resource-group litellm-prod --name litellm-aks \
--node-count 3 --enable-managed-identity
az postgres flexible-server create --resource-group litellm-prod \
--name litellm-db --database-name litellm \
--tier GeneralPurpose --sku-name Standard_D2ds_v5
az redis create --resource-group litellm-prod --name litellm-redis \
--location eastus --sku Standard --vm-size c1
Docs: AKS, Azure Database for PostgreSQL Flexible Server, Azure Cache for Redis. Azure Cache for Redis serves TLS on port 6380, and TLS is enabled through the URL scheme: instead of redis_host and redis_port, set redis_url: "rediss://:<access-key>@litellm-redis.redis.cache.windows.net:6380" under router_settings (the rediss:// scheme turns TLS on).
Deploy with Helm
First create the secrets both charts consume:
kubectl create secret generic litellm-masterkey \
--from-literal=masterkey="sk-$(openssl rand -hex 24)"
kubectl create secret generic litellm-db \
--from-literal=username=litellm \
--from-literal=password="<database-password>"
kubectl create secret generic litellm-env \
--from-literal=LITELLM_SALT_KEY="sk-$(openssl rand -hex 24)" \
--from-literal=REDIS_PASSWORD="<redis-password>" \
--from-literal=OPENAI_API_KEY="<provider-key>"
Then pick a deployment mode:
- Monolithic (litellm-helm)
- Microservices (litellm)
replicaCount: 3
image:
repository: ghcr.io/berriai/litellm-database
tag: "v1.90.2" # pin your version
masterkeySecretName: litellm-masterkey
masterkeySecretKey: masterkey
db:
useExisting: true
deployStandalone: false
endpoint: "<postgres-endpoint>"
database: litellm
secret:
name: litellm-db
usernameKey: username
passwordKey: password
environmentSecrets:
- litellm-env
proxy_config:
model_list:
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_API_KEY
router_settings:
redis_host: "<redis-endpoint>"
redis_port: 6379
redis_password: os.environ/REDIS_PASSWORD
helm install litellm oci://ghcr.io/berriai/litellm-helm -f values.yaml
The chart lives at deploy/charts/litellm-helm; the published chart versions carry LiteLLM release numbers (for example 1.90.2), and helm show values oci://ghcr.io/berriai/litellm-helm lists every knob. Beyond the values above it supports autoscaling (autoscaling.* or keda.*), PodDisruptionBudgets (pdb.*), a Prometheus ServiceMonitor (serviceMonitor.*), read replica routing (db.readReplicaUrl, see Database Read Replica), graceful drain on shutdown (lifecycle), and ArgoCD or Helm hooks for the migrations job (migrationJob.hooks.*, see Helm PreSync hooks).
masterKey:
secretName: litellm-masterkey
secretKey: masterkey
database:
writer:
host: "<postgres-endpoint>"
port: 5432
dbname: litellm
passwordSecret:
name: litellm-db
usernameKey: username
passwordKey: password
# optional: add database.reader to route reads to a replica
redis:
host: "<redis-endpoint>"
port: 6379
passwordSecret:
name: litellm-env
passwordKey: REDIS_PASSWORD
# one host fronting gateway, backend, and ui
ingress:
enabled: true
className: "<alb | gce | azure-application-gateway>"
host: llm.example.com
helm upgrade --install litellm \
oci://ghcr.io/berriai/litellm/chart/litellm \
--version 1.89.2 \
-f values.yaml
This deploys gateway, backend, and ui as separate services with per-component autoscaling, so you can run many gateway replicas against a small fixed backend. It requires external Postgres and Redis (no bundled subcharts) and supports reader/writer database splits, IAM database auth, and Redis Cluster mode. See Microservices Helm for the full values reference.
Both charts run the migrations job automatically and keep DISABLE_SCHEMA_UPDATE=true on the proxy pods. Expose the service through your cloud's ingress: the AWS Load Balancer Controller on EKS, GKE Ingress on GKE, or Application Gateway Ingress (AGIC) on AKS, with health checks on /health/readiness, then point your DNS record at the resulting load balancer. For secrets, prefer your cloud's secret manager over plain Kubernetes secrets (Key Vault CSI driver on AKS, for example); the charts consume whatever secret you mount.
Deploy with Terraform (AWS and GCP)
The official modules deploy the full microservices stack (network, database, Redis, object storage, secrets, compute, load balancer, and a migrations job that runs before the services start) and are published to the Terraform Registry:
- AWS (ECS Fargate)
- Google Cloud (Cloud Run)
Provisions a VPC with public and private subnets, an Aurora PostgreSQL cluster (writer plus reader, IAM database auth), ElastiCache Redis (multi-AZ, encrypted), an S3 bucket, Secrets Manager entries, an Application Load Balancer, and ECS Fargate services.
module "litellm" {
source = "BerriAI/litellm/aws"
version = "~> 1.90"
region = "us-east-1"
azs = ["us-east-1a", "us-east-1b"]
tenant = "acme"
env = "prod"
ui_password = var.ui_password
litellm_license = var.litellm_license # optional, omit for open source
acm_certificate_arn = var.acm_certificate_arn # TLS is required by default
proxy_config = {
model_list = [{
model_name = "gpt-4o"
litellm_params = {
model = "openai/gpt-4o"
api_key = "os.environ/OPENAI_API_KEY"
}
}]
}
gateway_extra_secrets = {
OPENAI_API_KEY = var.openai_key_secret_arn
}
}
Before you apply: provision the TLS certificate in AWS Certificate Manager (the module refuses a plaintext ALB unless you explicitly set allow_plaintext_alb = true), and create any provider-key secrets in Secrets Manager first, since gateway_extra_secrets takes their ARNs. After apply, point your DNS record at the ALB hostname.
The module auto-generates the master key into Secrets Manager if you do not supply one. The application connects to Aurora with short-lived IAM tokens, so its DATABASE_URL carries no password (the database master password itself is generated into Secrets Manager and never touches the application). Every resource is named <tenant>-litellm-<env>, and the module declares no provider, so you can for_each it to run one stack per tenant.
Provisions a VPC with Private Services Access, Cloud SQL PostgreSQL (primary plus read replica), Memorystore Redis with TLS, a GCS bucket, Secret Manager entries, Cloud Run services, and a global HTTPS load balancer with serverless NEGs.
module "litellm" {
source = "BerriAI/litellm/google"
version = "~> 1.90"
project_id = "my-project"
region = "us-central1"
tenant = "acme"
env = "prod"
ui_password = var.ui_password
litellm_license = var.litellm_license # optional
# Cloud Run cannot pull from ghcr.io. Point this at an Artifact Registry
# remote repository backed by ghcr.io, or mirror the images.
image_registry = "us-central1-docker.pkg.dev/my-project/ghcr-remote/berriai"
lb_domains = ["llm.example.com"]
proxy_config = {
model_list = [{
model_name = "gemini-2.5-pro"
litellm_params = { model = "vertex_ai/gemini-2.5-pro" }
}]
}
}
Three GCP-specific caveats. First, always override image_registry: it defaults to ghcr.io/berriai, which Cloud Run cannot pull from, so the apply succeeds but the services fail at image pull. Point it at an Artifact Registry remote repository that proxies ghcr.io. Second, the database uses password authentication through Secret Manager rather than IAM auth; LiteLLM's IAM token support is AWS RDS specific. Third, create the DNS record for lb_domains pointing at the load balancer IP after apply; the Google-managed certificate will not finish provisioning until the domain resolves to it.
Verify the deployment
Confirm the proxy is up and can reach its database:
curl -s https://llm.example.com/health/readiness
Then open the Admin UI at https://llm.example.com/ui and log in with your master key.
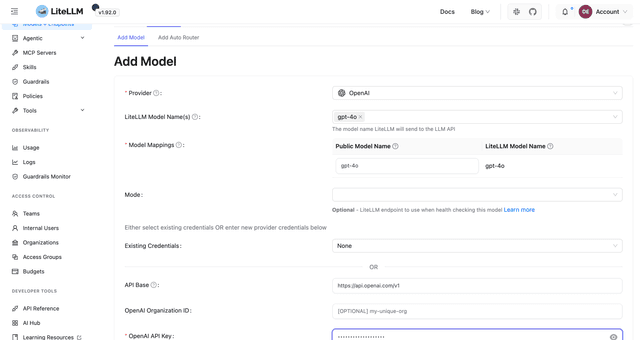
- Add a model. Go to Models + Endpoints and click Add Model: pick the provider, the model, and enter the provider credentials. With
STORE_MODEL_IN_DB=Truethe model is saved to your database, so you manage models here rather than in config files.
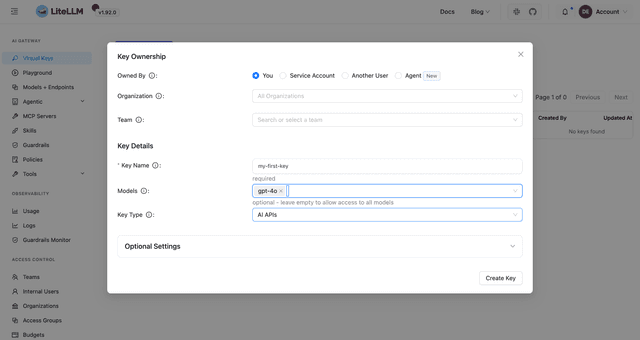
- Create a key. Go to Virtual Keys and click Create New Key, scoping it to the model you just added.
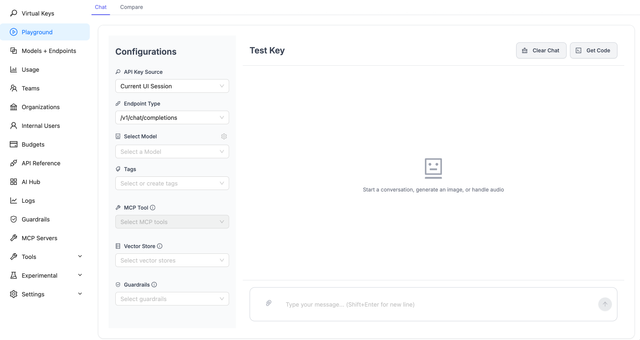
- Send a request. Go to the Test Key playground, select your key and model, and send a message. A response here proves the full path: load balancer, proxy, database, and provider credentials.
Next steps
Harden the deployment with the production checklist (worker counts, machine sizing, Redis settings, graceful degradation). Add regions with Multi-Region Deployment. For very high throughput (1000+ RPS), see resolving DB deadlocks.