Raw Request/Response Logging
Logging
See the raw request/response sent by LiteLLM in your logging provider (OTEL/Langfuse/etc.).
- SDK
- PROXY
# uv add langfuse
import litellm
import os
# log raw request/response
litellm.log_raw_request_response = True
# from https://cloud.langfuse.com/
os.environ["LANGFUSE_PUBLIC_KEY"] = ""
os.environ["LANGFUSE_SECRET_KEY"] = ""
# Optional, defaults to https://cloud.langfuse.com
os.environ["LANGFUSE_HOST"] # optional
# LLM API Keys
os.environ['OPENAI_API_KEY']=""
# set langfuse as a callback, litellm will send the data to langfuse
litellm.success_callback = ["langfuse"]
# openai call
response = litellm.completion(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "Hi 👋 - i'm openai"}
]
)
litellm_settings:
log_raw_request_response: True
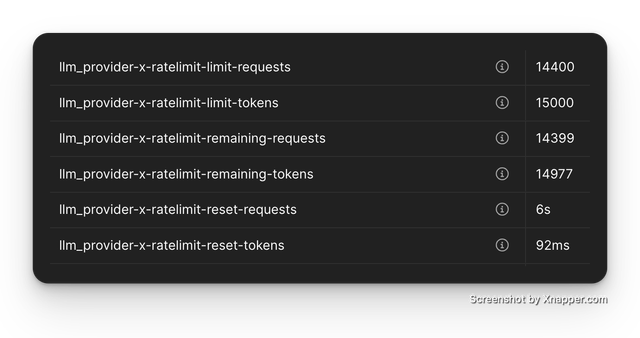
Expected Log

Return Raw Response Headers
Return raw response headers from llm provider.
Currently only supported for openai.
- SDK
- PROXY
import litellm
import os
litellm.return_response_headers = True
## set ENV variables
os.environ["OPENAI_API_KEY"] = "your-api-key"
response = litellm.completion(
model="gpt-3.5-turbo",
messages=[{ "content": "Hello, how are you?","role": "user"}]
)
print(response._hidden_params)
- Setup config.yaml
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
api_key: os.environ/GROQ_API_KEY
litellm_settings:
return_response_headers: true
- Test it!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-D '{
"model": "gpt-3.5-turbo",
"messages": [
{ "role": "system", "content": "Use your tools smartly"},
{ "role": "user", "content": "What time is it now? Use your tool"}
]
}'
Expected Response