OpenTelemetry v2
OpenTelemetry v2 (OTel v2) is LiteLLM Proxy's next-generation tracing. It gives you one clean trace per request that shows the whole story of a request — the incoming HTTP call, authentication, guardrails, the LLM call itself, and the internal database/cache work — all nested in a single tree.
It follows standard OpenTelemetry GenAI semantic conventions, so the traces it produces are readable in any OTel backend (Grafana Tempo, Jaeger, Honeycomb, Datadog, …) and come with ready-made presets for popular LLM observability tools (Arize, Phoenix, Langfuse, Weave, Langtrace, Levo, AgentOps).
OTel v2 is off by default. Nothing in it runs until you set LITELLM_OTEL_V2=true. It is separate from the existing OpenTelemetry integration — pick one. If you are moving from v1, see Migrating to OpenTelemetry v2.
What you get
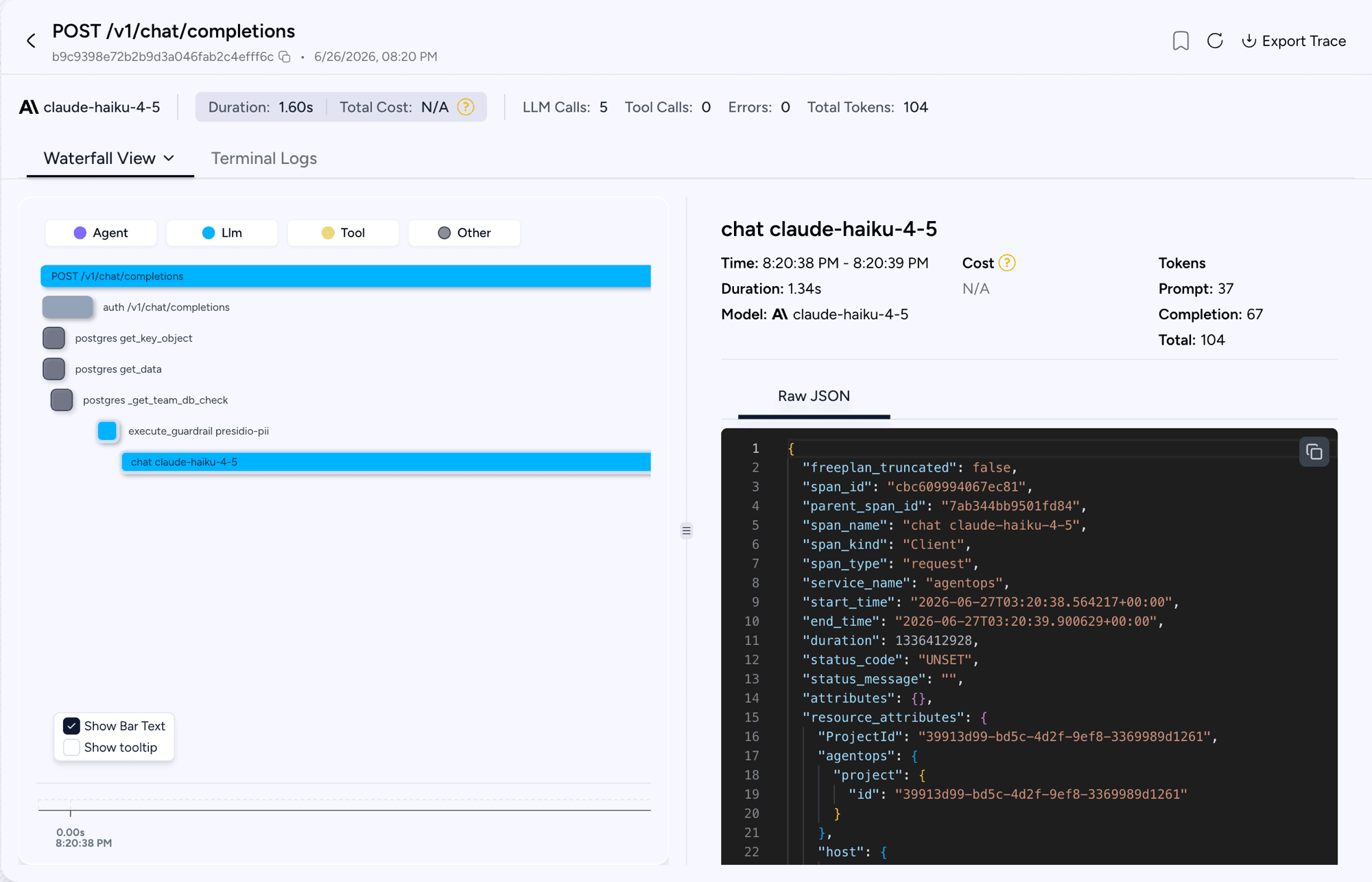
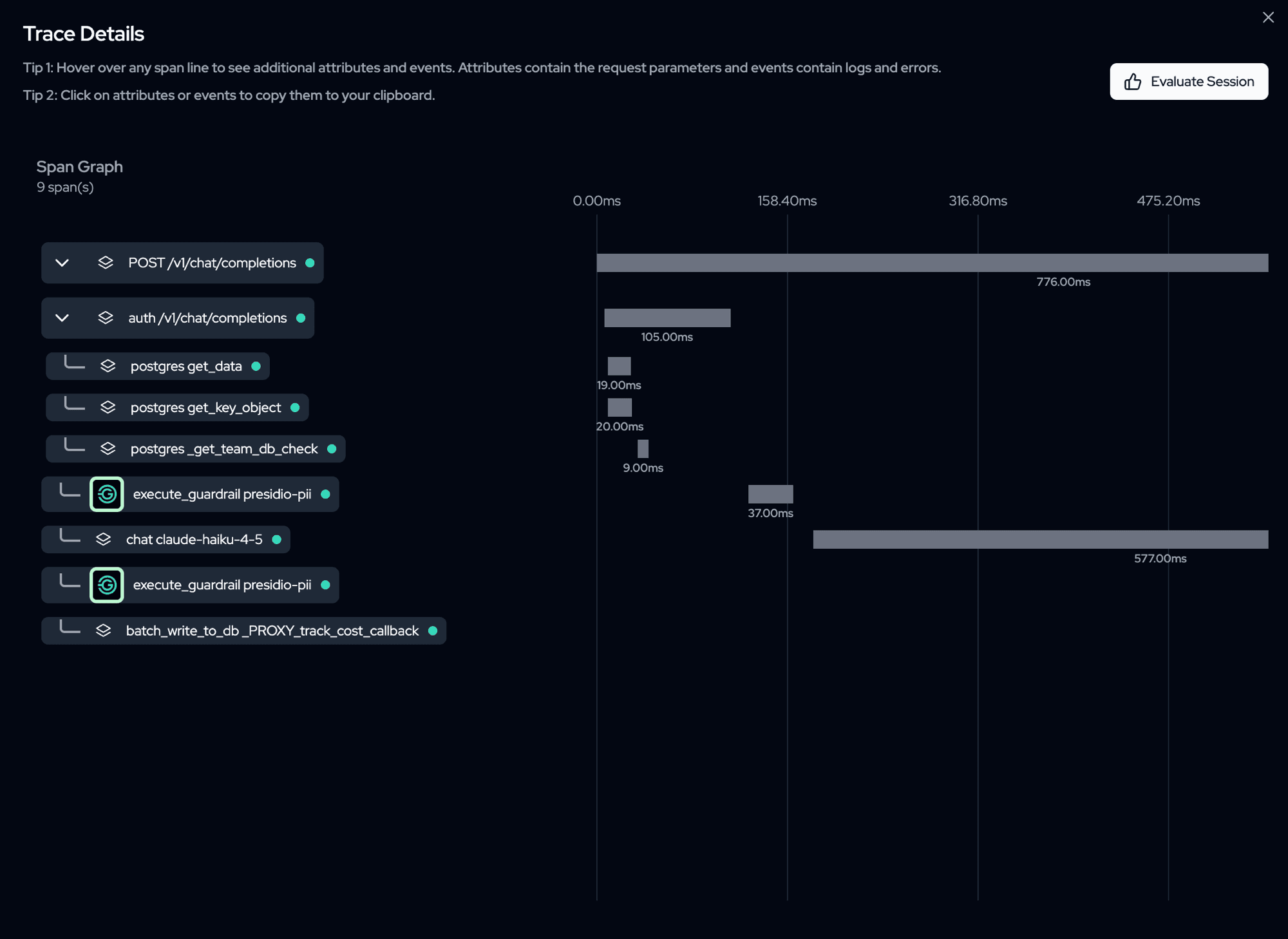
A single request to your proxy produces one trace that looks like this:
POST /v1/chat/completions ← HTTP request (server span)
├── auth /v1/chat/completions ← authentication
│ ├── postgres get_key_object ← DB lookups during auth
│ └── postgres get_team_membership
├── execute_guardrail presidio-pii ← each guardrail that runs
├── chat gpt-4o ← the LLM call (model, tokens, cost)
└── batch_write_to_db ← spend/usage written to DB
Highlights:
- One trace, end to end — the HTTP request, auth, guardrails, the LLM call, and DB writes all live in the same trace, correctly nested.
- Rich GenAI attributes — every LLM-call span carries
gen_ai.*attributes: model, provider, token usage, cost, finish reasons, request parameters, and more. - Standards-based — built on the official OpenTelemetry GenAI semantic conventions, so it works with any OTel-compatible backend.
- Vendor presets — one line to ship traces to Arize, Phoenix, Langfuse, Weave, Langtrace, Levo, or AgentOps in the format each tool expects.
- Safe by default — prompts and responses are not captured unless you explicitly opt in. Noisy routes (health checks, metrics scrapes, UI assets) are excluded automatically.
- Distributed tracing — if your client sends a
traceparentheader, LiteLLM's spans nest inside your existing trace.
Getting started
Set LITELLM_OTEL_V2=true in the proxy environment, then pick a destination below.
1. Send traces to any OTLP collector
This path sends spans over OTLP (the OpenTelemetry Protocol) to a collector or backend you are already running at the endpoint below; if you do not have one yet, stay on the console exporter from the Quickstart until you do. Set the feature flag plus the standard OTEL_* environment variables in the proxy's environment. No config change is needed.
- OTLP HTTP collector
- OTLP gRPC collector
LITELLM_OTEL_V2=true
OTEL_EXPORTER="otlp_http"
OTEL_ENDPOINT="http://localhost:4318"
LITELLM_OTEL_V2=true
OTEL_EXPORTER="otlp_grpc"
OTEL_ENDPOINT="http://localhost:4317"
gRPC export needs
grpcio. Install withpip install grpcio.
Pass auth headers your backend needs via OTEL_HEADERS:
OTEL_HEADERS="api-key=your-key,x-tenant=acme"
Then start the proxy as usual:
litellm --config config.yaml
Make a request, and you'll see one trace per request in your backend.
2. Send traces to a specific tool (presets)
For LLM observability tools, use a preset. A preset knows the tool's endpoint and emits attributes in the schema that tool expects. To enable one, add its name to callbacks in your config and set the tool's credentials as env vars.
- Arize
- Arize Phoenix
- Langfuse
- Weave (W&B)
- Langtrace
- Levo
- AgentOps
litellm_settings:
callbacks: ["arize"]
LITELLM_OTEL_V2=true
ARIZE_SPACE_ID="your-space-id"
ARIZE_API_KEY="your-api-key"
ARIZE_PROJECT_NAME="your-project-name" # required: Arize rejects spans with no project
litellm_settings:
callbacks: ["arize_phoenix"]
LITELLM_OTEL_V2=true
PHOENIX_API_KEY="your-api-key"
PHOENIX_COLLECTOR_ENDPOINT="https://app.phoenix.arize.com/v1/traces"
PHOENIX_PROJECT_NAME="my-project" # optional
litellm_settings:
callbacks: ["langfuse_otel"]
LITELLM_OTEL_V2=true
LANGFUSE_PUBLIC_KEY="pk-..."
LANGFUSE_SECRET_KEY="sk-..."
LANGFUSE_HOST="https://cloud.langfuse.com" # or your self-hosted URL
litellm_settings:
callbacks: ["weave_otel"]
LITELLM_OTEL_V2=true
WANDB_API_KEY="your-api-key"
WANDB_PROJECT_ID="your-entity/your-project"
Langtrace does not accept litellm's OTLP spans directly. It ingests JSON-encoded OTLP at a custom path (/api/trace) with an x-api-key header, whereas litellm v2 sends protobuf to /v1/traces. Run an OpenTelemetry Collector between them: litellm exports to the collector, and the collector re-encodes the spans to JSON and forwards them to Langtrace. The langtrace callback still applies Langtrace's attribute schema; the collector only handles delivery.
litellm_settings:
callbacks: ["langtrace"]
LITELLM_OTEL_V2=true
OTEL_ENDPOINT="http://otel-collector:4318"
Collector config (otel-collector-config.yaml), with LANGTRACE_API_KEY set in the collector's environment:
receivers:
otlp:
protocols:
http:
endpoint: 0.0.0.0:4318
exporters:
otlphttp/langtrace:
encoding: json
compression: none
traces_endpoint: https://app.langtrace.ai/api/trace
headers:
x-api-key: ${env:LANGTRACE_API_KEY}
Content-Type: application/json
service:
pipelines:
traces:
receivers: [otlp]
exporters: [otlphttp/langtrace]
litellm_settings:
callbacks: ["levo"]
LITELLM_OTEL_V2=true
LEVOAI_API_KEY="your-api-key"
LEVOAI_ORG_ID="your-org-id"
LEVOAI_WORKSPACE_ID="your-workspace-id"
LEVOAI_COLLECTOR_URL="your-levo-collector-url" # contact Levo support for this
litellm_settings:
callbacks: ["agentops"]
LITELLM_OTEL_V2=true
AGENTOPS_API_KEY="your-api-key"
To send the same traces to multiple vendors, list each preset in callbacks and set each one's env vars. For example, Langfuse and Arize together:
litellm_settings:
callbacks: ["langfuse_otel", "arize"]
Each preset adds its own destination, so your spans reach all of them in parallel, each in that tool's native format.
Preset reference
Every preset turns into one exporter on a single shared tracer. The table lists, for each one, the callback name you put in callbacks, the credentials it reads, where it sends, the attribute vocabulary it adds on top of the canonical gen_ai.* keys, and whether it supports per-request (per-team/key) credentials.
| Preset | Callback | Required env vars | Optional env vars | Destination | Vocabulary | Per-request creds |
|---|---|---|---|---|---|---|
| Arize AX | arize | ARIZE_SPACE_ID (ARIZE_SPACE_KEY deprecated), ARIZE_API_KEY, ARIZE_PROJECT_NAME | ARIZE_ENDPOINT (gRPC, default https://otlp.arize.com/v1), ARIZE_HTTP_ENDPOINT (HTTP) | Arize AX platform | OpenInference | Yes |
| Arize Phoenix | arize_phoenix | PHOENIX_API_KEY | PHOENIX_COLLECTOR_HTTP_ENDPOINT or PHOENIX_COLLECTOR_ENDPOINT (gRPC), PHOENIX_PROJECT_NAME | Phoenix (self-hosted or Phoenix Cloud) | OpenInference | No |
| Langfuse | langfuse_otel | LANGFUSE_PUBLIC_KEY, LANGFUSE_SECRET_KEY | LANGFUSE_HOST (or LANGFUSE_OTEL_HOST; default https://us.cloud.langfuse.com, EU is https://cloud.langfuse.com), OTEL_IGNORE_CONTEXT_PROPAGATION (set true to drop inbound traceparent) | Langfuse Cloud or self-hosted | Langfuse | Yes |
| Weave (W&B) | weave_otel | WANDB_API_KEY, WANDB_PROJECT_ID (<entity>/<project>) | WANDB_HOST (default https://trace.wandb.ai) | Weights & Biases Weave | OpenInference + Weave | Yes |
| Langtrace | langtrace | none of its own | — | Langtrace, via an OpenTelemetry Collector (Langtrace ingests JSON-only OTLP) | Langtrace | No |
| Levo | levo | LEVOAI_API_KEY, LEVOAI_ORG_ID, LEVOAI_WORKSPACE_ID, LEVOAI_COLLECTOR_URL | LEVOAI_ENV_NAME | Levo collector | canonical gen_ai.* only | No |
| AgentOps | agentops | AGENTOPS_API_KEY | AGENTOPS_SERVICE_NAME (default agentops), AGENTOPS_ENVIRONMENT (default production) | AgentOps (https://otlp.agentops.cloud) | canonical gen_ai.* only | No |
Notes:
- Arize AX vs Arize Phoenix are different backends from the same company. AX (
arize) is the hosted platform; Phoenix (arize_phoenix) is the open-source tracer you self-host or run on Phoenix Cloud. They use different credentials and endpoints, so pick the callback for the backend you actually run. You can also enable both at once to send to each. - Langtrace ingests JSON-only OTLP at a custom path, so litellm v2 (which sends protobuf to
/v1/traces) cannot export to it directly. Route through an OpenTelemetry Collector that re-encodes to JSON; thelangtracepreset only adds the Langtrace attribute schema to your spans. See the Langtrace tab above for the collector config. - Vocabulary is additive: every preset's spans always carry the canonical OpenTelemetry
gen_ai.*attributes; the listed vocabulary is layered on top so the destination tool reads its native schema.
Seeing your traces
Once a backend is configured with its preset, each request shows up in that tool's UI as a chat <model> span under the request root. Each tab below covers the vendor-specific gotchas (project mapping, endpoint variants, metadata keys) that trip people up.
- Arize
- Arize Phoenix
- Langfuse
- Weave (W&B)
- AgentOps
- Langtrace
- Levo
- Generic OTLP
What Arize renders
Open your Arize project; the trace appears under the project named by ARIZE_PROJECT_NAME. The openinference mapper stamps the OpenInference vocabulary onto the LLM-call span alongside the canonical gen_ai.* keys, so Arize reads its native schema without dropping the canonical ones.
Attributes added by the openinference mapper
| Attribute | Restates |
|---|---|
openinference.span.kind | Fixed LLM |
llm.model_name, llm.provider | model, provider |
llm.token_count.prompt, completion, total | usage split |
llm.invocation_parameters | JSON blob of request params |
llm.input_messages.{idx}.message.role, content | prompt (content capture on) |
llm.output_messages.{idx}.message.role, content | response (content capture on) |
input.value, output.value | JSON arrays of the same (content capture on) |
llm.tools.{idx}.tool.name, description, json_schema | tool definitions |
See the full OpenInference spec for the definitive vocabulary.
Setup notes
ARIZE_SPACE_KEYis the deprecated name forARIZE_SPACE_ID; the preset still reads it for backward compatibility, but preferARIZE_SPACE_IDin new configs.
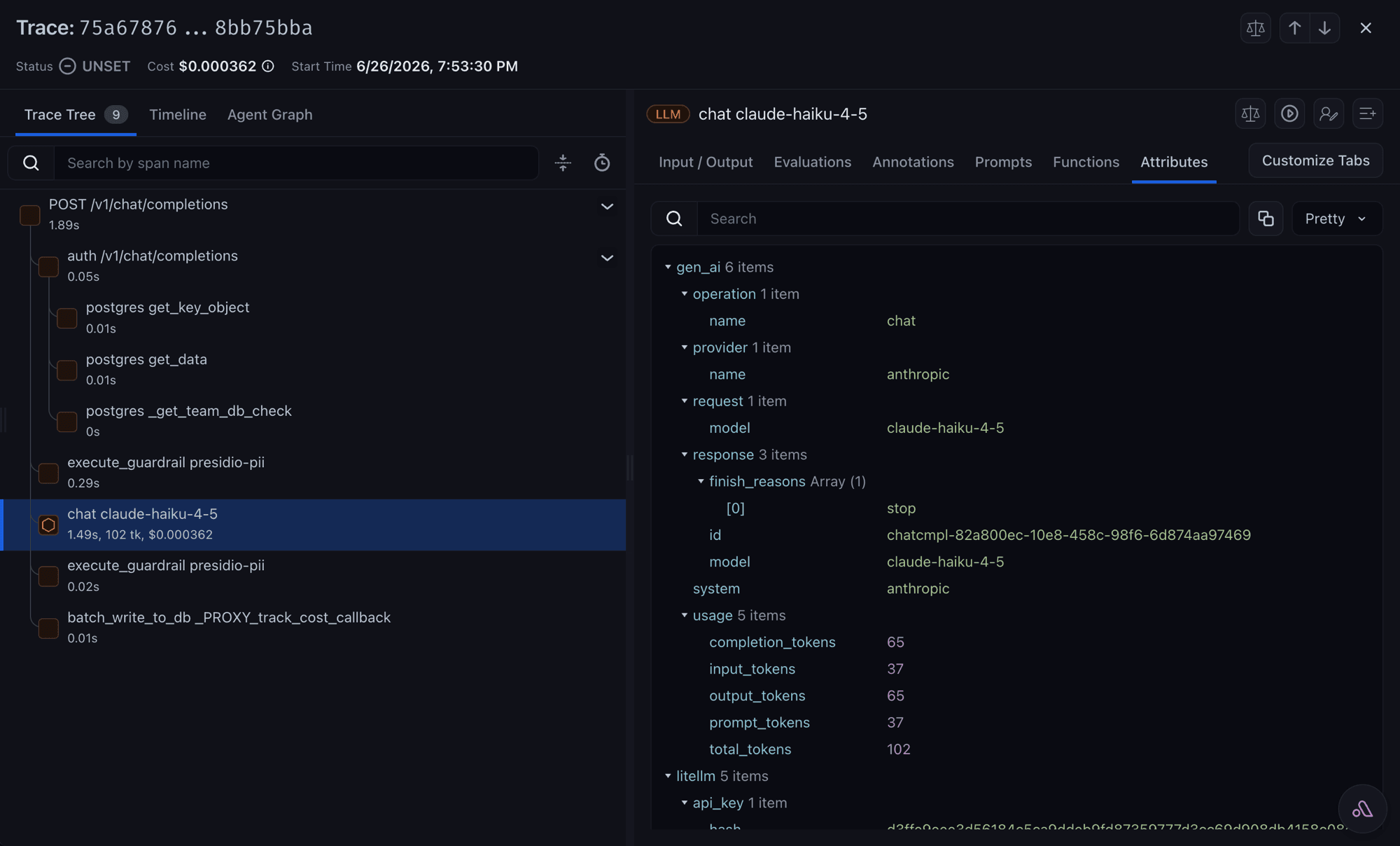
What Phoenix renders
Open Phoenix; the project comes from PHOENIX_PROJECT_NAME (default default), stamped as the openinference.project.name resource attribute. Phoenix uses the same OpenInference vocabulary as Arize AX.
Attributes added by the openinference mapper
Same as the Arize tab above.
Setup notes
Phoenix has more than one collector endpoint shape, and picking the wrong one is the most common Phoenix setup mistake. Point PHOENIX_COLLECTOR_HTTP_ENDPOINT (or PHOENIX_COLLECTOR_ENDPOINT for gRPC) at the shape that matches your deployment:
| Deployment | Endpoint |
|---|---|
| Phoenix Cloud (Spaces) | https://app.phoenix.arize.com/s/<space-name>/v1/traces |
| Phoenix Cloud (legacy) | https://app.phoenix.arize.com/legacy/v1/traces |
| Phoenix Cloud (old) | https://app.phoenix.arize.com/v1/traces |
| Self-hosted | http://localhost:6006/v1/traces |
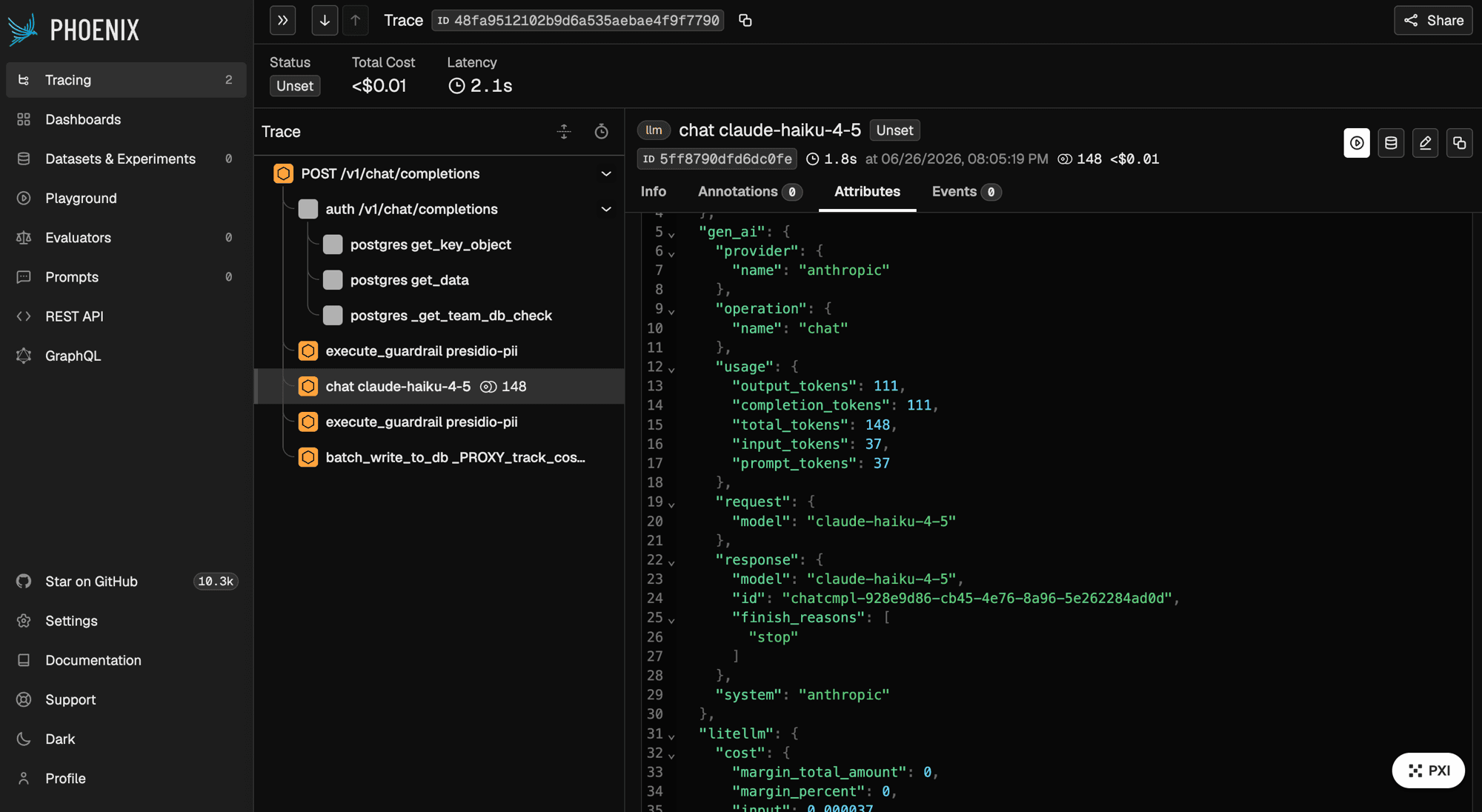
What Langfuse renders
Open the Langfuse traces view; the LLM-call span appears as a Langfuse generation, filterable by team. Endpoint resolution is LANGFUSE_OTEL_HOST, then LANGFUSE_HOST, then the US cloud default, with /api/public/otel appended for a self-hosted host.
Attributes added by the langfuse mapper
| Attribute | Purpose |
|---|---|
langfuse.observation.type | Fixed generation so this span appears as a model call |
langfuse.observation.model.name | Model shown on the generation |
langfuse.observation.model.parameters | JSON of request params (temperature, top_p, max_tokens, penalties, seed) |
langfuse.observation.id | Same as litellm.call_id |
langfuse.observation.input / output | Prompt and response bodies (content capture on) |
langfuse.observation.usage_details | Input/output/total token counts |
langfuse.observation.cost_details | Total cost |
langfuse.trace.metadata.team_id, team_alias | Filterable team identity |
These are set by the preset from the request and response, not from a client-supplied metadata dict, so you get them without extra config.
Setup notes
- Auth is HTTP Basic,
Authorization: Basic <base64(public_key:secret_key)>; the preset builds this fromLANGFUSE_PUBLIC_KEYandLANGFUSE_SECRET_KEYso you never set the header directly. - If your client already sends a W3C
traceparentand Langfuse is picking up the wrong parent, setOTEL_IGNORE_CONTEXT_PROPAGATION=truein the proxy environment to drop inbound context. - This is a Langfuse-flavored path; for a general-purpose OTel backend, use the generic OTLP setup instead.
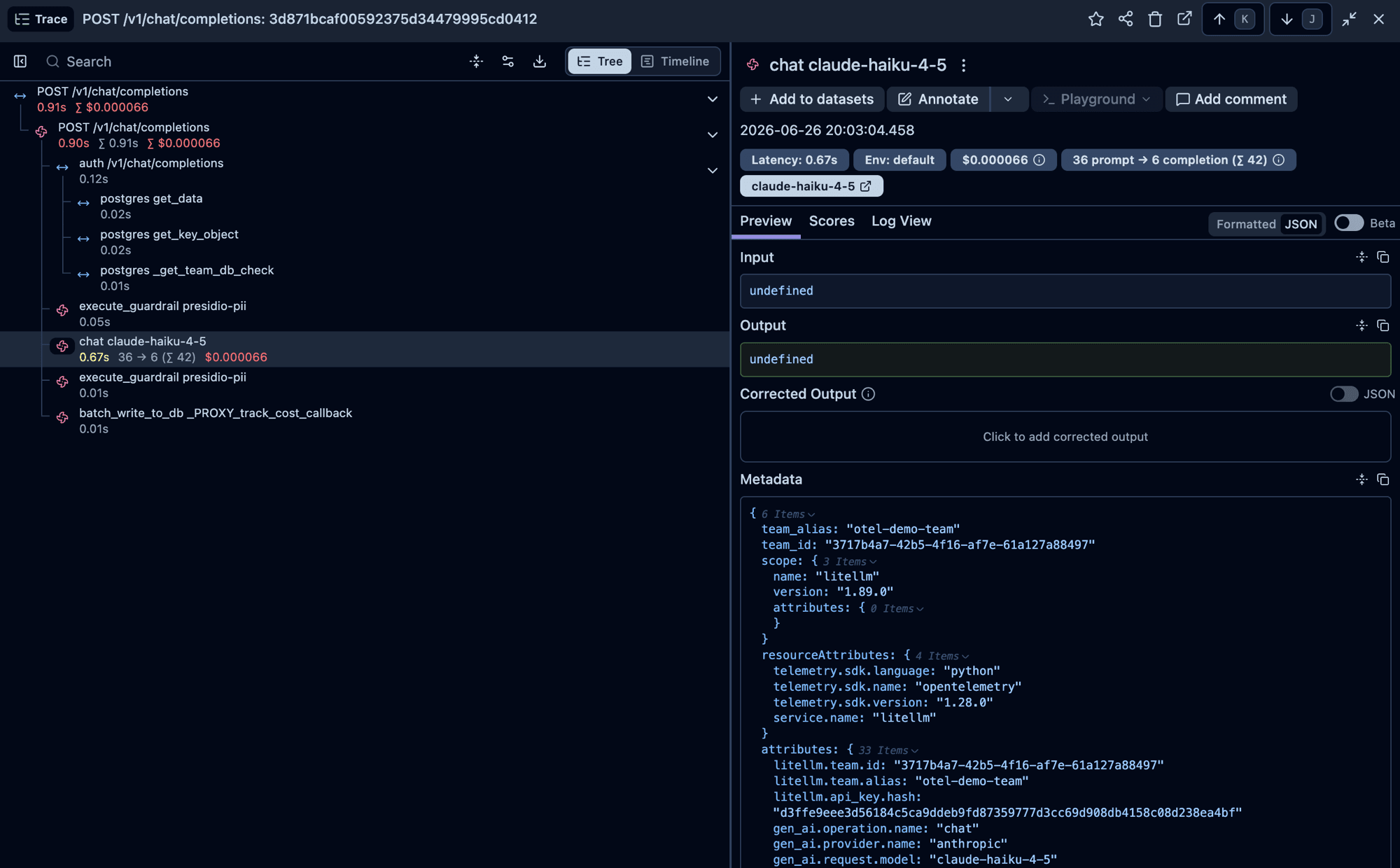
What Weave renders
Open the Weave project at wandb.ai/<entity>/weave. Weave consumes OpenInference plus a small Weave overlay, so the weave_otel preset composes both mappers on the same span.
Attributes added by the weave mapper
The openinference mapper (see the Arize tab) runs first, then the weave mapper adds:
| Attribute | Purpose |
|---|---|
weave.display_name | "{operation} {model}" (e.g. chat gpt-4o) |
weave.call_id | Same as litellm.call_id |
weave.output | JSON array of choices (content capture on) |
Setup notes
WANDB_PROJECT_IDmust be inentity/projectform, which is the most common setup mistake.- The
weave_otelpreset is the OTel-based Weave integration and is unrelated to the olderwandbsuccess-callback logger (which uses thewandbPython package and writes to W&B directly, not through OTel); see the W&B legacy page if you're looking for that one.
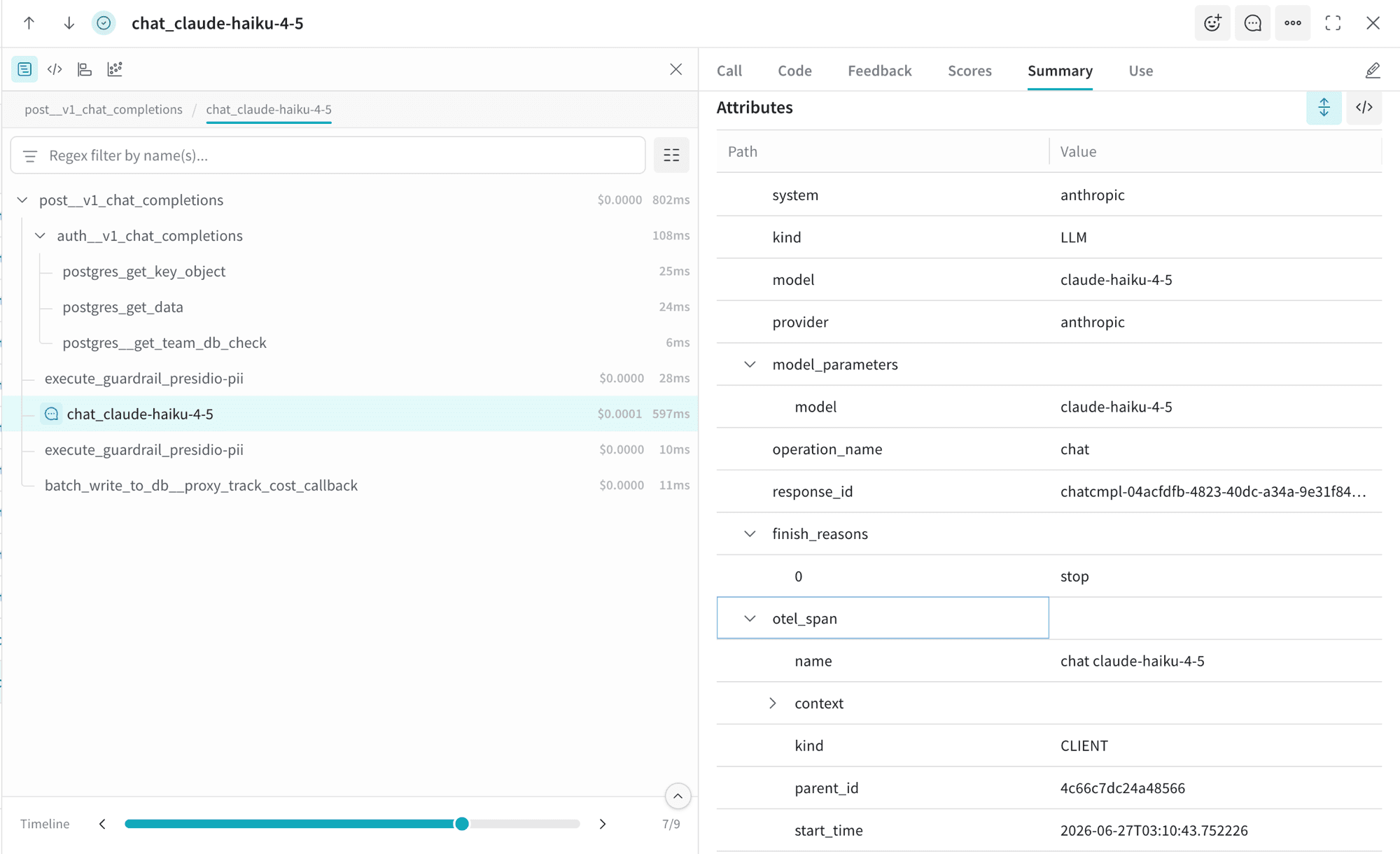
What AgentOps renders
Open the AgentOps dashboard. AgentOps does not add a vendor mapper, so spans arrive in the canonical gen_ai.* schema (plus legacy if enabled).
Attributes added by the AgentOps preset
No vendor mapper is added, so the LLM-call span carries only the canonical keys listed in Span attributes. The preset controls two resource-level labels on the traces:
| Attribute | Purpose |
|---|---|
service.name | From AGENTOPS_SERVICE_NAME (default agentops) |
deployment.environment | From AGENTOPS_ENVIRONMENT (default production) |
Setup notes
- AgentOps mints its auth token on the first span export rather than at startup, so the very first export can look briefly delayed; this happens once per process and is expected.
- Set
AGENTOPS_SERVICE_NAME/AGENTOPS_ENVIRONMENTif you want to separate environments in the AgentOps UI.
What Langtrace renders
Open the Langtrace UI; the spans flow through your OpenTelemetry Collector carrying the langtrace.* and llm.* keys.
Attributes added by the langtrace mapper
| Attribute | Restates |
|---|---|
langtrace.service.name | provider |
llm.model, gen_ai.response.model, gen_ai.response_id, gen_ai.system_fingerprint | request/response identifiers |
llm.temperature, top_p, top_k, max_tokens, frequency_penalty, presence_penalty | request params |
llm.stream | streaming flag |
llm.token.counts.prompt, completion, total | usage split |
llm.prompts, llm.completions | JSON arrays (content capture on) |
Setup notes
Langtrace ingests JSON-only OTLP at a custom path, so litellm exports through an OpenTelemetry Collector that re-encodes to JSON. See the Langtrace tab under Getting started for the collector configuration.
What Levo renders
Open the Levo dashboard. Levo does not add a vendor mapper, so spans arrive in the canonical gen_ai.* schema (plus legacy if enabled).
Attributes added by the Levo preset
No vendor mapper is added. Traces carry only the canonical keys from Span attributes. The preset routes spans to LEVOAI_COLLECTOR_URL with Authorization: Bearer $LEVOAI_API_KEY, plus x-levo-organization-id and x-levo-workspace-id headers built from LEVOAI_ORG_ID and LEVOAI_WORKSPACE_ID.
Setup notes
- The collector URL is used as-is, no path manipulation, so provide the exact URL Levo gave you.
LEVOAI_ENV_NAMEis optional and tags spans with an environment label in the Levo UI.
What a generic OTLP backend renders
Whatever your backend's UI shows for standard OTel GenAI spans. The generic preset (and the plain env-var OTLP path from Getting started section 1) does not add a vendor mapper.
Attributes added
None beyond the canonical gen_ai.* and litellm.* keys listed in Span attributes, plus the legacy Traceloop keys if LITELLM_OTEL_LEGACY_COMPAT=true.
Setup notes
Use this path for Jaeger, Grafana Tempo, Honeycomb, Datadog, SigNoz, Splunk Observability Cloud, and any other backend that consumes standard OTLP. If a backend is not listed above and there is no dedicated tab, this is the one to use.
Capturing prompts & responses
By default, OTel v2 records metadata only (model, tokens, cost, timing) and never writes prompt or response text to your traces. This is intentional — it keeps sensitive content out of your observability backend.
To capture message content, opt in explicitly:
# no_content (default) — never capture prompts/responses
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT="no_content"
# span_only — write prompts/responses as attributes on spans
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT="span_only"
# event_only — write prompts/responses on log events instead of span attributes
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT="event_only"
# span_and_event — write content to both spans and events
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT="span_and_event"
The gate is enforced centrally, so it applies to every backend at once — a user request can never force its prompt into your backend while capture is disabled.
Span attributes
Attributes come from a chain of mappers stamped onto each span in order. The canonical genai mapper is always applied first, the legacy compatibility mapper is on by default, and each preset adds one vendor mapper on top. Later mappers can override earlier ones; the same span therefore carries several vocabularies describing the same call.
The first two tables cover the LLM-call span in the canonical vocabulary. Sections below list the other span kinds, then what each vendor mapper adds.
LLM-call span, canonical gen_ai.* + litellm.*
Request-side keys:
| Attribute | When set |
|---|---|
gen_ai.operation.name | always (chat, text_completion, embeddings) |
gen_ai.provider.name | always |
gen_ai.request.model | always (the user-facing model group name) |
gen_ai.request.temperature, top_p, top_k, max_tokens | when set on the request |
gen_ai.request.frequency_penalty, presence_penalty, seed | when set |
gen_ai.request.stop_sequences | when set (string array) |
gen_ai.tool.{idx}.name, description, parameters | one set per tool definition |
server.address, server.port | when the provider endpoint is known |
Response, usage, cost, identity:
| Attribute | When set |
|---|---|
gen_ai.response.id, gen_ai.response.model | on success |
gen_ai.response.finish_reasons | on success (string array) |
gen_ai.usage.input_tokens, gen_ai.usage.output_tokens | on success |
gen_ai.input.messages, gen_ai.output.messages | content capture on |
gen_ai.system_instructions | content capture on, when a system prompt is present |
litellm.call_id | always |
litellm.provider.model | always (the model string actually sent to the provider) |
litellm.request.streaming | when true |
litellm.cost.total | on success |
litellm.cost.input, output, cache_read, cache_creation, tool_usage | when the source reported the breakdown |
litellm.cost.original, discount_amount, discount_percent, margin_fixed_amount, margin_percent, margin_total_amount | when reported |
Status and errors:
- On failure: the span records the standard
exceptionevent (exception.type,exception.message), setserror.typefrom the exception class, and sets its status toERROR. - On success: the status is left
UNSET(the semconv default, matching the FastAPI server span). Only a genuine error setsERROR, so do not key an alert on a status ofOK.
Other span kinds
Guardrail span — uses the litellm.guardrail.* namespace: name, mode, status, provider, action, response, violation_categories, confidence_score, risk_score, masked_entity_count, duration, id, policy_template, detection_method. status is one of success, guardrail_intervened, guardrail_failed_to_respond, or not_run; a blocking guardrail_intervened or guardrail_failed_to_respond also sets span status to ERROR.
Datastore span (redis, postgres) — db.system.name, db.operation.name, litellm.service.name, litellm.service.call_type.
Internal service span — the litellm.service.* keys only (no db.*).
MCP tool-call span — gen_ai.operation.name=execute_tool, mcp.method.name, mcp.session.id, gen_ai.tool.name, litellm.mcp.server.name, litellm.call_id, litellm.cost.total. gen_ai.tool.call.arguments and gen_ai.tool.call.result are gated by the same content-capture setting as prompt content.
Root HTTP server span — the HTTP semconv keys http.request.method, http.route, http.response.status_code, url.path, stamped by the FastAPI instrumentation (not by any of LiteLLM's mappers).
Each vendor preset also composes one vendor-specific mapper on top of these canonical keys, so the destination reads the trace in its native schema. Those per-vendor tables live under the matching Seeing your traces tab.
Attribute conventions
LiteLLM emits one canonical set of GenAI attributes and layers other vocabularies on top by adding a mapper; the active set is controlled by mapper_names, with genai always first. The legacy mapper is on by default (LITELLM_OTEL_LEGACY_COMPAT=true) and re-emits the same data under the older semconv-ai / Traceloop names, so dashboards built against those keep working through a migration. Turn it off with LITELLM_OTEL_LEGACY_COMPAT=false once your queries use the canonical keys. Vendor mappers (openinference, langfuse, weave, langtrace) are added by their presets and never replace the canonical keys.
The most common keys line up across vocabularies as follows:
Canonical (genai) | Legacy (Traceloop) | OpenInference |
|---|---|---|
gen_ai.usage.input_tokens | gen_ai.usage.prompt_tokens | llm.token_count.prompt |
gen_ai.usage.output_tokens | gen_ai.usage.completion_tokens | llm.token_count.completion |
gen_ai.provider.name | gen_ai.system | llm.provider |
litellm.request.streaming | llm.is_streaming | n/a |
gen_ai.request.model | n/a | llm.model_name |
Request identity on every span
LiteLLM writes a small allowlist of request-identity values into standard OpenTelemetry Baggage at the auth boundary. A custom span processor then copies those values onto every span in the trace, so a guardrail, datastore, or service span is filterable by team or key without LiteLLM re-stamping each one by hand.
By default the following keys are written onto every span:
| Key | Value |
|---|---|
litellm.team.id | Team UUID |
litellm.team.alias | Team display name |
litellm.team.metadata | Team's free-form metadata, filtered to the sub-keys you allowlist |
litellm.api_key.hash | Hash of the caller's virtual key |
gen_ai.request.model | User-facing model group name |
litellm.provider.model | Dispatched model on the provider |
A separate set of request-metadata fields is written under the litellm.metadata.* namespace. Defaults:
litellm.metadata.user_api_key_org_id, litellm.metadata.user_api_key_user_id, litellm.metadata.user_api_key_alias, litellm.metadata.user_api_key_end_user_id, litellm.metadata.requester_ip_address.
Two defaults stay conservative for privacy. The end-user id is promotable but off by default at the top level (it identifies an individual); it appears under litellm.metadata.user_api_key_end_user_id, which callers who filter by user should enable. A team's free-form metadata is never emitted whole; only the sub-keys you allowlist leave the process, and the allowlist is empty by default.
Override any of these with the LITELLM_OTEL_BAGGAGE_PROMOTED_KEYS, LITELLM_OTEL_BAGGAGE_METADATA_KEYS, and LITELLM_OTEL_BAGGAGE_TEAM_METADATA_KEYS env vars (comma-separated), or the matching YAML lists under callback_settings.otel.
Metrics
Alongside traces, OTel v2 can emit GenAI client metrics: histograms for call latency, token usage, and cost that your backend aggregates across requests. Like the rest of OTel v2 they stay off until you turn them on.
Set the flag in the proxy environment next to LITELLM_OTEL_V2:
LITELLM_OTEL_V2=true
LITELLM_OTEL_INTEGRATION_ENABLE_METRICS=true
Metrics ship through the exporter you already configured for traces. OTEL_EXPORTER (console, otlp_http, otlp_grpc), OTEL_ENDPOINT, and OTEL_HEADERS decide where the metric stream goes exactly as they do for spans, so the collector that receives your traces receives the metrics too.
What's recorded
Each successful LLM call records the standard OpenTelemetry GenAI client metrics:
| Metric | Unit | What it measures |
|---|---|---|
gen_ai.client.operation.duration | s | Wall-clock time for the whole LLM call |
gen_ai.client.token.usage | {token} | Tokens consumed, split into input and output by the gen_ai.token.type attribute |
gen_ai.client.token.cost | USD | LiteLLM's computed cost for the call |
gen_ai.client.response.time_to_first_token | s | Time to the first streamed token (streaming calls) |
gen_ai.client.response.time_per_output_token | s | Average time per output token |
gen_ai.client.response.duration | s | Provider-side generation time |
Every sample carries the same identity attributes as the matching span (operation, provider/system, request model, framework, and selected metadata.* fields), so you can group the histograms by model, provider, key, or team. These are the same six metrics the v1 OpenTelemetry integration emits, with identical names and units, so a dashboard built for one reads the other.
Control metric attribute cardinality
By default every metric sample is stamped with the full identity attribute set, which includes per-request fields such as hidden_params and several metadata.* values. Those are close to unique per request, so each one multiplies the number of time series your backend tracks (one series per distinct attribute combination). At volume this explodes metric cardinality, and some backends, for example Splunk Observability Cloud, start throttling or dropping the metrics.
v2 reads the same filter v1 does, from callback_settings.otel.attributes in your config. Nest an attributes block there with either an include_list (allowlist; emit only the listed attributes) or an exclude_list (denylist; emit everything except the listed attributes). The two are mutually exclusive. The filter applies to metrics only; spans keep their full attribute set, so traces stay rich while metric cardinality stays bounded.
The block sits under callback_settings.otel. With LITELLM_OTEL_V2 set, listing otel in callbacks builds the v2 logger and reads this block (it builds the legacy v1 logger only when the flag is off); the block is also read on the default path when no otel callback is listed.
Unlike v1, v2 has no per-instance attributes field, so this global block is the only source. v2 also resolves the filter lazily on the first metric a request records rather than at boot, so a bad config (both lists set, or a forbidden name) surfaces on that first recorded request and editing the lists takes effect only after a restart. The filter is read only on the default OTLP path (callback name otel or unset); preset destinations such as arize, arize_phoenix, and langfuse_otel emit their metrics with the full attribute set, the same as in v1.
callback_settings:
otel:
attributes:
exclude_list:
- hidden_params
- metadata.requester_metadata
- metadata.requester_ip_address
- metadata.spend_logs_metadata
- metadata.mcp_tool_call_metadata
- metadata.vector_store_request_metadata
- metadata.prompt_management_metadata
When you want the smallest, most predictable attribute set, list exactly the attributes to keep with include_list. Anything not listed is dropped from metrics:
callback_settings:
otel:
attributes:
include_list:
- gen_ai.operation.name
- gen_ai.system
- gen_ai.request.model
- gen_ai.framework
- metadata.user_api_key_team_id
- metadata.user_api_key_org_id
gen_ai.token.type is never filtered out. It is stamped on gen_ai.client.token.usage after the filter runs, so the input/output split survives whatever list you set, and naming it in either include_list or exclude_list is rejected.
Which routes are traced
High-frequency, non-LLM routes are excluded by default so they don't flood your traces: health checks (/health*), the Prometheus scrape (/metrics), and static UI/docs assets (/ui, /docs, /redoc, /_next, /openapi.json, favicons, …).
To change the set, use the standard OpenTelemetry env var (comma-separated paths, substring-matched):
# Trace everything, including health checks
OTEL_PYTHON_FASTAPI_EXCLUDED_URLS=""
# Exclude only your own custom paths
OTEL_PYTHON_FASTAPI_EXCLUDED_URLS="/health,/internal"
Per-key / per-team destinations (multi-tenant)
One proxy can serve many tenants and send each tenant's traces only to that tenant's own backend, so a team never sees another team's traces. The proxy admin owns the routing; a team or key just points at a destination by name and never handles another tenant's secrets.
Proxy admin Team admin
creates a destination ───────► picks it from a list
(backend + secrets + scope) (only ones in their scope show up)
│ │
└──────────► at request time ◄─────────┘
the proxy matches caller to destination
and sends that request's trace there
The idea in one minute
There are two pieces.
A destination is a named place to send traces, created by the proxy admin. It reuses the same backends and credentials as the presets above: it holds which backend it is (langfuse_otel, arize, weave_otel, or a generic OTLP endpoint, meaning any backend that speaks the OpenTelemetry Protocol), the connection details and secrets for that backend, and an access scope that says which teams or organizations are allowed to use it. An organization here is a group of teams; a team belongs to one org.
A team, key, or organization turns a destination on by listing its name in a setting called logging_exporters. That is the only thing a team admin ever touches; the secrets stay with the proxy admin.
At request time the proxy looks at the key that made the call, the team that key belongs to, and that team's organization, collects every destination name those three list, keeps only the destinations whose access scope actually includes this caller, and sends the request's trace to each one. If nothing matches, the trace goes only to your normal global exporter from the sections above.
Who can change what
Three roles appear below. The proxy admin runs the whole proxy and holds every secret. An org admin runs one organization (a group of teams). A team admin runs a single team. The split exists so a team admin can opt their own team in without ever seeing or editing another tenant's secrets.
| Action | Proxy admin | Org admin (of the team's org) | Team admin (of the team) |
|---|---|---|---|
| Create or delete a destination | Yes | No | No |
| Edit a destination's backend, host, or secrets | Yes | No | No |
| Make a destination global, or grant it to whole orgs | Yes | No | No |
| Grant a destination to a team | Yes, any team | Yes, teams in their org | Yes, their own team |
Turn a destination on for a team or key (logging_exporters) | Yes | Yes | Yes (their team) |
Set it up in the UI
This is the common path, and it always takes two things to be true before a team's traces flow: the destination's access scope must include the team, and the team must list the destination in its Logging Exporters. The admin handles the first; the team admin handles the second. Note these are two different screens: the admin works in Settings, Logging Callbacks (where destinations are created), and the team admin works in a team's Logging Exporters picker (where a destination is switched on).
Proxy admin, create the destination:
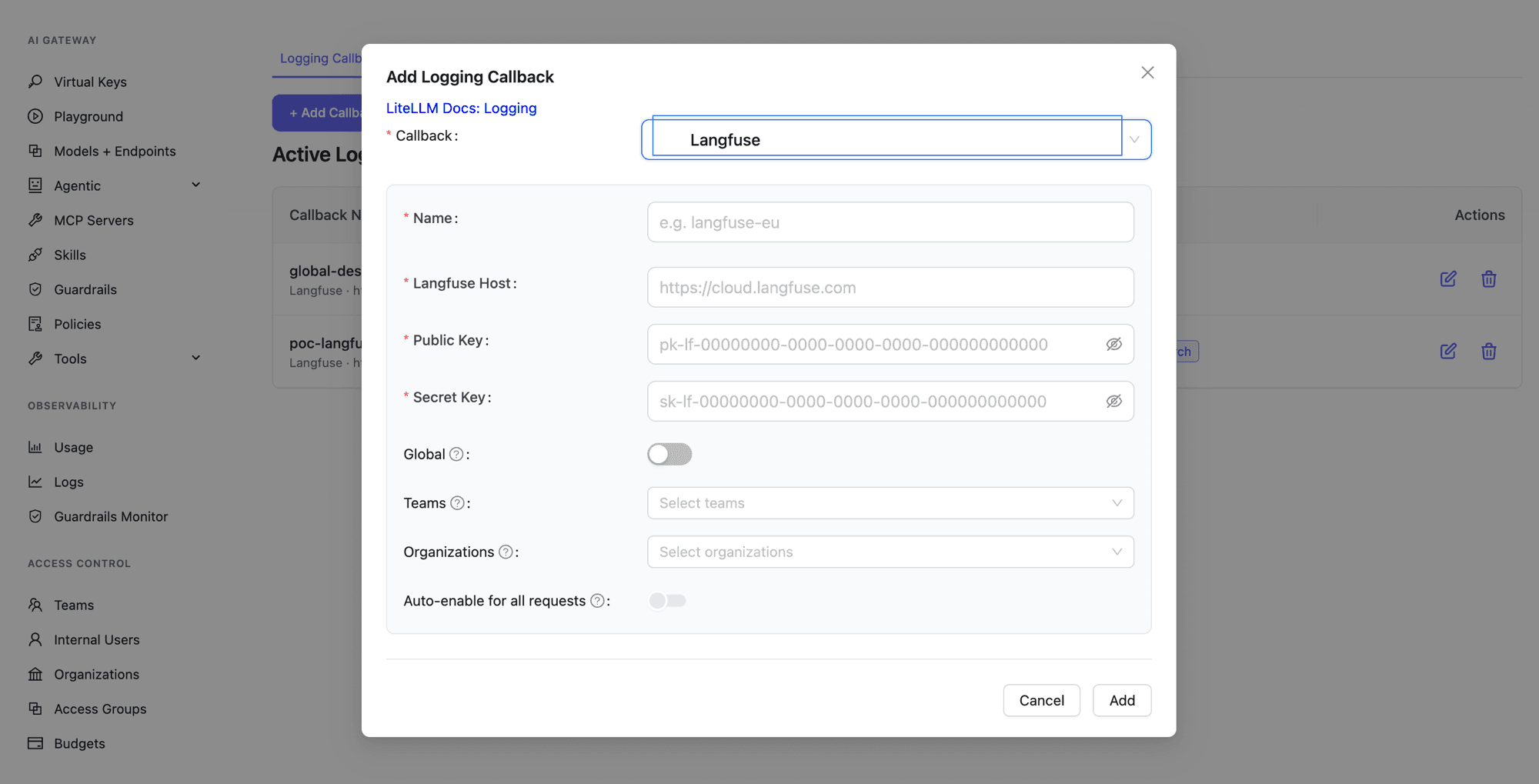
- Open the proxy UI and go to Settings, then Logging Callbacks.
- Click to add a logging destination. Choose the backend (
langfuse_otel,arize,weave_otel, orgeneric), fill in the host and the secrets for that backend, and set the Access scope: make it Global (every team), or pick specific Teams or Orgs. The secret values are the same ones you would set as that preset's env vars, copied from the backend's own dashboard (for example, your Langfuse project's API keys); see the Preset reference for which fields each backend needs. - Save. From now on the secrets and the Global/Org scope are admin-only; team admins can only attach the destination to teams already in its scope.
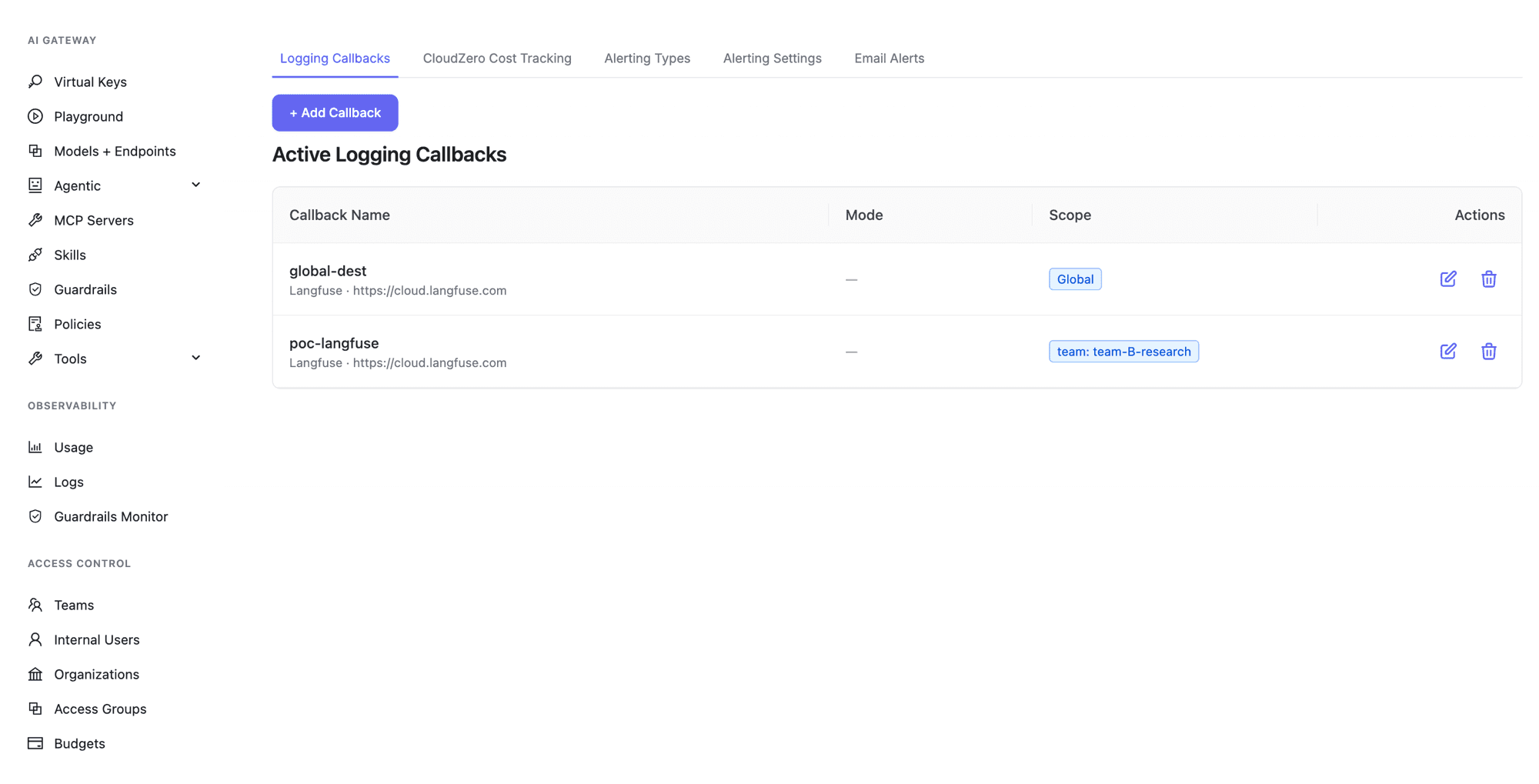
The destinations you create appear in the Logging Callbacks list, each tagged with its access scope:
Team admin, switch it on for a team:
- Go to Teams, pick your team, open Settings (or go to Virtual Keys, pick a key, and edit it).
- In the Logging Exporters multi-select, choose the destination. Only destinations in your scope appear here; other tenants' destinations are never listed.
- Save. Every request from that team or key now also sends its trace to the destination you picked.
Set it up over the API
The UI calls these endpoints; you can use them directly. The placeholders are: $ADMIN_KEY is a proxy-admin virtual key and $TEAM_ADMIN_KEY is the team admin's virtual key (mint either on the Virtual Keys page in the UI, or with /key/generate), <team-id> comes from the Teams page, and pk-... / sk-... are the backend's own keys from its dashboard. As in the UI, both the grant (step 1 or 2) and the turn-on (step 3) must be done before traces flow.
Step 1, proxy admin creates a destination (here a Langfuse destination granted to one team):
curl -X POST http://localhost:4000/credentials \
-H "Authorization: Bearer $ADMIN_KEY" -H "Content-Type: application/json" \
-d '{
"credential_name": "tenant-a-langfuse",
"credential_values": {
"langfuse_public_key": "pk-...",
"langfuse_secret_key": "sk-...",
"langfuse_host": "https://cloud.langfuse.com"
},
"credential_info": {
"credential_type": "logging",
"description": "langfuse_otel",
"host": "https://cloud.langfuse.com",
"access": { "teams": ["<team-id>"] }
}
}'
credential_type must be logging, and description names the backend. Step 2 (an alternative to the grant in step 1): a team admin grants their own team with a narrow patch, and cannot touch secrets, host, or the global/org scope:
curl -X PATCH http://localhost:4000/credentials/tenant-a-langfuse \
-H "Authorization: Bearer $TEAM_ADMIN_KEY" -H "Content-Type: application/json" \
-d '{"credential_info": {"access": {"teams": ["<their-team-id>"]}}}'
Step 3, turn the destination on for a team by adding its name to the team's logging_exporters:
curl -X POST http://localhost:4000/team/update \
-H "Authorization: Bearer $TEAM_ADMIN_KEY" -H "Content-Type: application/json" \
-d '{"team_id": "<team-id>", "metadata": {"logging_exporters": ["tenant-a-langfuse"]}}'
The same metadata.logging_exporters works on a key (/key/update) and on an organization, and the proxy unions all three at request time.
Backends and the fields each one needs
The admin fills these into the destination's secret fields; the values come from the backend's own dashboard, the same as the preset env vars in the Preset reference. Anything OTLP-compatible that is not one of the first three uses generic.
Backend (description) | Secret fields |
|---|---|
langfuse_otel | langfuse_public_key, langfuse_secret_key, langfuse_host (optional; defaults to Langfuse US cloud) |
arize | arize_space_id (or arize_space_key), arize_api_key, arize_project_name; arize_endpoint optional |
weave_otel | wandb_api_key, weave_project_id (optional); weave_endpoint optional |
generic | otel_endpoint (required), otel_headers (optional, key=value,key2=value2) |
Good to know
Resolution is default-deny: a team only reaches a destination it both lists in logging_exporters and is in scope for. A misconfigured or misspelled name simply sends nothing, rather than leaking a trace to the wrong tenant.
Two shortcuts skip the per-team opt-in, and both are admin-only, set on the destination itself. A destination marked global is available to every team without an admin granting it team by team; a team admin still lists it to turn it on. A destination marked auto-enable goes further and applies to every request automatically, without any team listing it at all; use it when you want one backend to capture every request's trace across the whole proxy. In the UI both are toggles in the destination modal next to the Access scope; over the API they are credential_info.access.global and credential_info.auto_enable, for example:
curl -X PATCH http://localhost:4000/credentials/tenant-a-langfuse \
-H "Authorization: Bearer $ADMIN_KEY" -H "Content-Type: application/json" \
-d '{"credential_info": {"auto_enable": true}}'
This routing applies to traces only. The GenAI client metrics (see Metrics) still go to your single globally-configured exporter, not to per-tenant destinations.
Distributed tracing
If the incoming request has a W3C traceparent header, LiteLLM continues that trace instead of starting a new one. Your LiteLLM spans then appear inline inside whatever distributed trace your application already has — so you can follow a request from your app, through the proxy, to the LLM provider, in one view.
Configuration reference
All values are environment variables. Boolean flags accept true/false.
| Variable | Default | Purpose |
|---|---|---|
LITELLM_OTEL_V2 | false | Master switch. OTel v2 does nothing until this is true. |
OTEL_EXPORTER (alias OTEL_EXPORTER_OTLP_PROTOCOL) | console | Exporter kind: console, otlp_http, otlp_grpc. |
OTEL_ENDPOINT (alias OTEL_EXPORTER_OTLP_ENDPOINT) | none | OTLP collector URL. Setting an endpoint implies otlp_http unless you override OTEL_EXPORTER. |
OTEL_HEADERS (alias OTEL_EXPORTER_OTLP_HEADERS) | none | Comma-separated key=value auth headers for your backend. |
OTEL_SERVICE_NAME | litellm | service.name resource attribute shown in your backend. |
OTEL_ENVIRONMENT_NAME | none | deployment.environment resource attribute (e.g. production). |
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT | no_content | Prompt/response capture: no_content, span_only, event_only, span_and_event. |
OTEL_PYTHON_FASTAPI_EXCLUDED_URLS | health/metrics/UI routes | Comma-separated paths to exclude from tracing (substring match). Set to "" to trace everything. |
LITELLM_OTEL_INTEGRATION_ENABLE_METRICS | false | Also emit the GenAI client metrics (duration, token usage, cost, streaming timings). See Metrics. |
LITELLM_OTEL_LEGACY_COMPAT | true | Also emit attributes under the older Traceloop key names. See Attribute conventions. |
The full set of keys on each span kind is in Span attributes.
Troubleshooting
No traces showing up?
- Confirm
LITELLM_OTEL_V2=trueis set in the proxy's environment. - Try
OTEL_EXPORTER="console"first — if spans print to stdout, the problem is your exporter endpoint/headers, not LiteLLM. - Make sure you hit an LLM route (e.g.
/v1/chat/completions). Health checks and UI routes are excluded by default. - Check that
opentelemetry-instrumentation-fastapiis installed (see Requirements).
Only see the LLM call but no auth/postgres/server span? Those server and DB spans require the FastAPI instrumentation package — install opentelemetry-instrumentation-fastapi.
I see metadata but no prompts/responses. That's the default. Set OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT=span_only to capture content.
Support
For questions, open an issue at BerriAI/litellm.